


The challenge isn’t storing data cloud storage is cheap. The real challenge is making data queryable, shareable, and consistently structured across teams using different tools, update cycles, and access controls.
According to Snowflake’s latest annual report, over 9,000 organizations globally use its Data Cloud for analytics and data engineering workloads.
Why Snowflake Is Transforming Modern Data Engineering (Top Snowflake Use Cases Overview)
Snowflake simplifies data engineering by separating compute from storage in the cloud. For example, a team running a heavy quarterly report can scale up a larger virtual warehouse for a few hours and pay only for that usage without affecting other teams running concurrent workloads.
Because compute and storage scale independently, teams can run heavy workloads such as quarterly reports on larger virtual warehouses for a short time and pay only for the compute resources they actually use, without impacting other concurrent workloads.
Cloud-Native Architecture, Compute-Storage Separation, and Scalability
Snowflake’s snowflake architecture separates compute and storage, making it ideal for modern data pipeline architecture design.
- Independent scaling of compute and storage
- Supports structured and semi-structured data using Snowflake’s VARIANT column type (JSON, Avro, Parquet)
- Built for data lifecycle management and data reliability
- Enables cloud data warehouses across AWS, Azure, and GCP
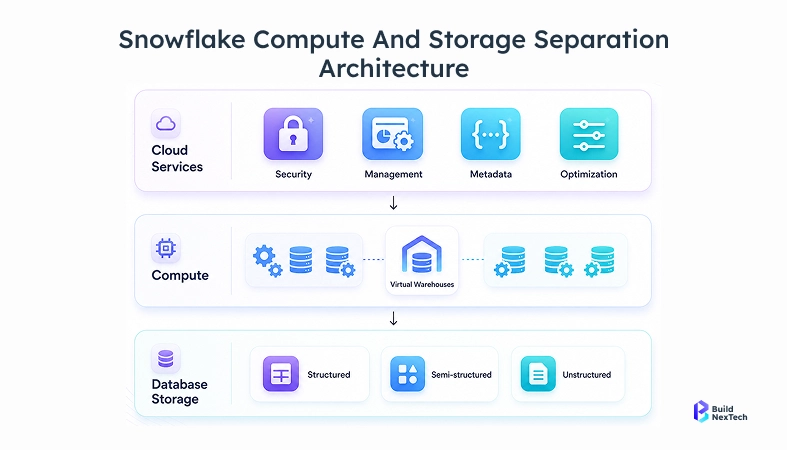
This architecture enables organizations to develop snowflake scalable data pipeline systems without any concerns about infrastructure bottlenecks, which makes it a robust recommendation in use on production platforms supporting ML workloads and AI models.
Snowflake vs BigQuery: Performance and Cost Comparison
When comparing Snowflake vs Google BigQuery, performance and pricing flexibility stand out.
Note: Pricing as of April 2026. Verify latest pricing on Snowflake and Google BigQuery official pricing pages, as costs vary by region and usage.
Quick Summary
- Choose Snowflake if you need:
- Fine-grained performance control
- Predictable BI workloads
- Multi-cloud flexibility
- Choose BigQuery if you need:
- Fully serverless experience
- Real-time analytics and ad-hoc querying
- Minimal infrastructure management
Top Snowflake Use Cases for Real-Time Streaming and Data Pipeline Architectures
Modern data engineering requires pipelines that process data as it arrives. Snowflake enables this through streaming ingestion, automated transformations, and seamless integration with external systems making it ideal for high-velocity data such as user events, financial transactions, and IoT streams.
Use Case 1: Real-Time Analytics with Snowflake Streaming Pipelines (Snowpipe + Streams)
Business Problem:
Across various systems, operational and application data is created, including ERP, CRM, and event platforms, yet they update at varying rates. This lag renders teams to lack access to timely insights, which in most cases compels them to use old reports in decision making.
How Snowflake Helps:
Snowflake ingests data continuously via Snowpipe and processes incremental changes through Streams and Tasks. This ensures data is updated in near real time, and allows teams to construct streaming pipelines to dashboards, IoT data, and user activity tracking. Consequently, organizations gain faster visibility into operations and can make better decisions.
Use Case 2: Event-Driven Data Pipelines with Kafka Integration
Business Problem:
The current applications result in a nonstop stream of events, yet batch processing introduces lags and reduces responsiveness. In distributed systems, data is often fragmented across services, making it difficult to build a unified view.
How Snowflake Helps:
Snowflake can be integrated with Apache Kafka to enable the ingestion and analysis of event streams in real-time. This allows organizations to process data in real time as it is created and create a unified data view such as Customer 360 to enhance operational decisions and workloads of AI/ML.
Use Case 3: Automated ELT Pipelines Using Tasks and Streams
Business Problem:
Managing ETL workflows across multiple tools introduces multiple failure points—each adding compounding pressure on consistency and accuracy.
How Snowflake Helps:
Snowflake makes the development of snowflake etl pipelines simple with Tasks to schedule and Streams to capture incremental changes. This automation saves on manual effort, enhances data lineage, and ensures the same quality of data, enabling teams to operate data pipelines more effectively.
Designing Low-Latency and Scalable Data Pipeline Architectures
Designing efficient snowflake data ingestion pipeline systems requires careful planning to ensure performance, scalability, and reliability across growing workloads.
- Use clustering keys to improve SQL query performance and reduce latency.
- Optimize warehouse sizing to handle concurrency and avoid bottlenecks.
- Implement directed acyclic graph workflows using Apache Airflow.
- Monitor pipelines using data + AI observability tools like Monte Carlo.

In most Snowflake architectures, selecting the right clustering key has the highest impact—poor choices can increase query cost by 10–50x compared to optimized designs.
Snowflake Use Cases for Scalable ETL, Data Ingestion, and Transformation
Snowflake supports both ETL and ELT approaches. Teams can load raw data first and transform it later using SQL inside the platform, instead of pre-transforming before ingestion. This reduces pipeline failures and simplifies debugging.
Use Case 4: Incremental Data Loading with Change Data Capture (CDC)
Business Problem:
Reprocessing entire datasets for every update consumes time and resources, especially in systems where data changes frequently. This leads to inefficiencies and delays in making updated data available.
How Snowflake Helps:
Snowflake supports change data capture, allowing teams to process only modified data instead of full datasets. This reduces compute costs, improves processing speed, and ensures that data pipelines remain up to date, making it ideal for real-time analytics and reporting.
Use Case 5: Optimized Data Ingestion Using External Stages and Snowpipe
Business Problem:
Data arrives from multiple sources in different formats and at different times, making it difficult to standardize and prepare for analysis. This slows down the overall data pipeline and delays insights.
How Snowflake Helps:
Snowflake enables ingestion from external stages such as cloud storage and automates the process using Snowpipe. This ensures continuous data flow into the system, allowing teams to build efficient snowflake data ingestion pipeline solutions and quickly prepare data for analytics.
Data Transformation and Workflow Automation Techniques
Transformation is where raw data becomes actionable insights, and it plays a critical role in ensuring that data is accurate, consistent, and ready for analysis.
- Use data modeling (star/snowflake schema) to optimize query performance and reporting
- Apply business rules during transformation to standardize metrics across teams
- Enable Reverse ETL (using tools like Census or Hightouch) to push transformed Snowflake data back into CRMs, marketing platforms, and support tools—closing the loop between analytics and action
- Integrate with Apache Spark for large-scale transformations
Automated workflows ensure consistency and scalability across data pipelines, supporting BI reports, analytics, and data-driven decision-making across the organization.
Snowflake Use Cases in Modern Data Warehousing and Lakehouse Architectures
Modern organizations are moving beyond traditional systems and adopting flexible approaches that combine the strengths of both data warehouses and data lakes. Snowflake plays a key role in this shift by offering a unified cloud data warehouse that supports modern data lake architecture while maintaining high performance for analytics. And to maximize these capabilities, Organizations work with experienced snowflake consultants to design scalable and high-performing data architectures.
With its support for formats like Apache Iceberg and seamless integration with evolving data lake solutions, Snowflake enables a true lakehouse model where data can be accessed and transformed efficiently. This approach simplifies data engineering workflows, improves data lifecycle management, and ensures better data quality across the system.
Use Case 6: High-Performance Data Warehousing for BI Workloads
Business Problem:
As data volumes grow, traditional data warehouse systems struggle to maintain performance, leading to slower queries and delayed reporting. This affects the ability of teams to generate timely insights.
How Snowflake Helps:
Snowflake’s architecture separates compute and storage, allowing it to scale performance independently. This enables fast SQL query execution and supports large-scale business intelligence workloads, helping organizations build reliable BI dashboards using tools like Power BI.
Use Case 7: Data Lake Modernization with Snowflake Lakehouse
Business Problem:
Organizations often use separate systems for data lakes and data warehouses, which increases complexity and requires additional effort to manage pipelines and integrate data.
How Snowflake Helps:
Snowflake provides a unified platform that combines the capabilities of both systems, supporting modern data lake architecture with formats like Apache Iceberg and Delta Lake. This simplifies workflows and improves data lifecycle management while supporting analytics and AI/ML workloads.

Snowflake vs Databricks: Lakehouse Architecture Comparison
Comparing Snowflake with Databricks helps clarify use cases.
Quick Insight
- Choose Databricks for heavy machine learning, large-scale transformations, and open data lake architectures.
- Choose Snowflake for SQL-based analytics, high-performance data warehouse workloads, and seamless data sharing.
- Many enterprises use both Databricks for processing and Snowflake for analytics and reporting.
Snowflake Use Cases for Data Sharing, Integration, and Governance
In modern data engineering, organizations need seamless ways to share, integrate, and secure data across teams, partners, and regions. Snowflake addresses this by providing a unified cloud data platform that simplifies snowflake data sharing while maintaining strict data governance standards. Unlike traditional systems, it allows data to be shared in real time without duplication, making collaboration faster and more efficient across different business units and external stakeholders.
At the same time, Snowflake strengthens snowflake data integration by connecting with a wide connector ecosystem and supporting APIs for building flexible data pipelines. For example, a healthcare organization can share de-identified patient data with a research partner using dynamic data masking—allowing the partner to see aggregated values while internal teams retain full access, all from the same dataset.
Use Case 8: Secure Data Sharing with Data Exchange and Reader Accounts
Business Problem:
Sharing data through files or exports creates multiple versions, leading to inconsistencies and confusion among teams and partners. Managing access across different systems also becomes challenging.
How Snowflake Helps:
Snowflake allows organizations to share live data directly from a single source—without duplication or version conflicts. With features like the snowflake data marketplace, organizations can securely share data across teams and regions, ensuring consistency and improving collaboration.
Use Case 9: Data Governance with Role-Based Access Control (RBAC) and Dynamic Data Masking
Business Problem:
As data usage increases, controlling access and ensuring compliance becomes more complex. Without proper governance, sensitive data is at risk of unauthorized access.
How Snowflake Helps:
Snowflake provides built-in data governance features such as role-based access control (RBAC) and dynamic data masking. These capabilities help enforce the principle of least privilege, ensuring that data is secure while remaining accessible to authorized users.
Use Case 10: Multi-Cloud Data Integration and API-Driven Workflows
Business Problem:
Data is often distributed across multiple cloud platforms and systems, making integration difficult and increasing operational complexity. Teams struggle to access and analyze data in a unified way.
How Snowflake Helps:
Snowflake supports seamless snowflake data integration across AWS, Azure, and GCP, allowing organizations to work with data across environments without managing separate systems. This enables scalable, API-driven data pipelines and supports modern architectures, including AI-driven workflows.
Conclusion: How bnxt.ai Enhances Snowflake Use Cases in Data Engineering
Snowflake has become a strong foundation for modern data engineering, enabling scalable data pipelines, real-time analytics, and support for machine learning and AI Services. Its ability to handle everything from snowflake etl pipeline automation to data governance makes it a reliable platform for managing growing data needs.
- In bnxt.ai Snowflake migration projects, teams have reduced pipeline processing time by up to 40% by shifting from batch ETL systems to Snowpipe-based ingestion.
- This improvement comes from redesigning pipelines for real-time ingestion, optimizing warehouse usage, and reducing redundant data processing steps.
- Organizations adopting this approach gain faster data availability, lower compute costs, and more reliable pipeline performance.
By combining Snowflake’s powerful capabilities with bnxt.ai’s expertise, organizations can transform their core data platforms into intelligent, future-ready systems. This not only improves how data is managed and analyzed but also empowers businesses to innovate faster, respond to change more effectively, and unlock long-term value from their data.
People Also Ask

How does Snowflake handle change data capture (CDC) in real-time data pipelines?
Snowflake captures and processes incremental changes effectively with the help of Streams and Tasks. This guarantees real-time updates without reprocessing entire datasets and enhances performance and lowers costs.
What are the best ways to optimize query performance in Snowflake for large-scale workloads?
The most effective strategies for optimizing Snowflake query performance at scale include using clustering keys to reduce data scanned, right-sizing virtual warehouses for concurrency, enabling result caching, and analyzing query profiles to identify bottlenecks.
How does Snowflake integrate with tools like Kafka, dbt, and Airflow in data engineering workflows?
Snowflake integrates with Apache Kafka for real-time event stream ingestion, dbt for SQL-based transformations with lineage tracking, and Apache Airflow for orchestrating multi-step pipeline workflows—covering ingestion, transformation, and scheduling across the full ELT pipeline.
What are the cost optimization strategies when designing Snowflake data pipelines?
The most effective Snowflake cost optimization strategies include enabling auto-suspend on virtual warehouses, implementing change data capture (CDC) to avoid full reprocessing, and monitoring usage through the ACCOUNT_USAGE schema.
How does Snowflake support multi-cloud data architectures and cross-region data sharing?
Snowflake can run on AWS, Azure, and GCP, which means that it could be deployed on multiple clouds and enable secure data sharing across regions without data duplication.





.webp)
.webp)
.webp)

