

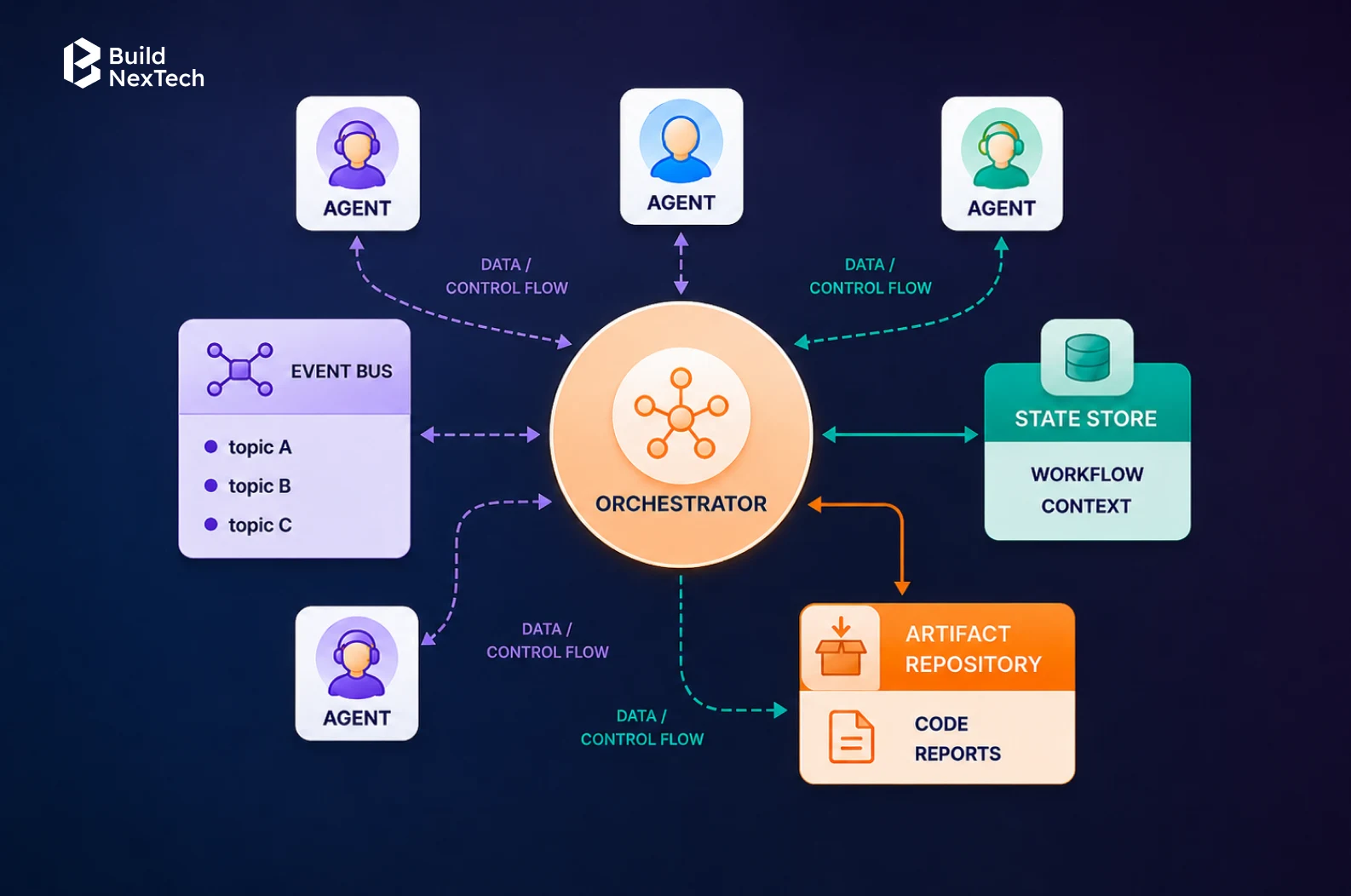
Eight months into building a multi-agent system, a fintech company came to us with a strange problem: every individual agent was doing its job correctly, but the system as a whole wasn't. Their customer service pipeline, made up of a triage agent, a compliance check agent, and a document processing agent, was quietly producing wrong outputs several times a day. The agents worked. The handoffs between them didn't. And because nothing in the pipeline tracked where things broke down, no one could pinpoint which agent was responsible or why the failure was happening. The business had deployed agentic AI and still had three people manually auditing outputs every morning. That is not automation. That is automation with extra steps.
AI agent orchestration is the control layer that separates a working demo from a production system. According to a 2025 MIT study, 95% of generative AI pilots fail to deliver measurable financial impact - not because models underperform, but because teams underinvest in coordination architecture. Across 150+ client engagements spanning CRM systems, financial underwriting pipelines, and enterprise workflows in 30+ industries, that pattern holds without exception.
This guide covers the orchestration patterns that reach production, the state and handoff architecture that prevents cascade failures, and the observability requirements you need before go-live.
Why Single-Agent Systems Hit a Production Ceiling
Single agents fail at scale for three structural reasons - none fixed by upgrading to a more capable model.
The first is domain overload: routing precision degrades sharply past around 15 to 20 tools. The second is context collapse - long task chains cause earlier instructions to decay out of the context window, so downstream decisions happen on incomplete information. The third is the governance bottleneck. A single agent cannot enforce granular security controls, produce per-step audit logs, or support human-in-the-loop checkpoints without significant custom engineering bolted on top.
These are design constraints, not model quality problems. The answer is architectural: decompose tasks, distribute them across specialised agents, and build a coordination layer that manages delegation, shared state, and failure across the full agent lifecycle management cycle.
The Coordination Tax of Scaling Agent Count Without Architecture
Adding more agents without disciplined agent definitions, task delegation schemas, and state contracts degrades system performance. Communication overhead grows non-linearly. The real cost most teams do not budget for is building the orchestration layer that makes multi-agent systems behave deterministically - and that is the primary reason agentic orchestration projects stall before reaching production.
The Three Orchestration Patterns That Actually Reach Production
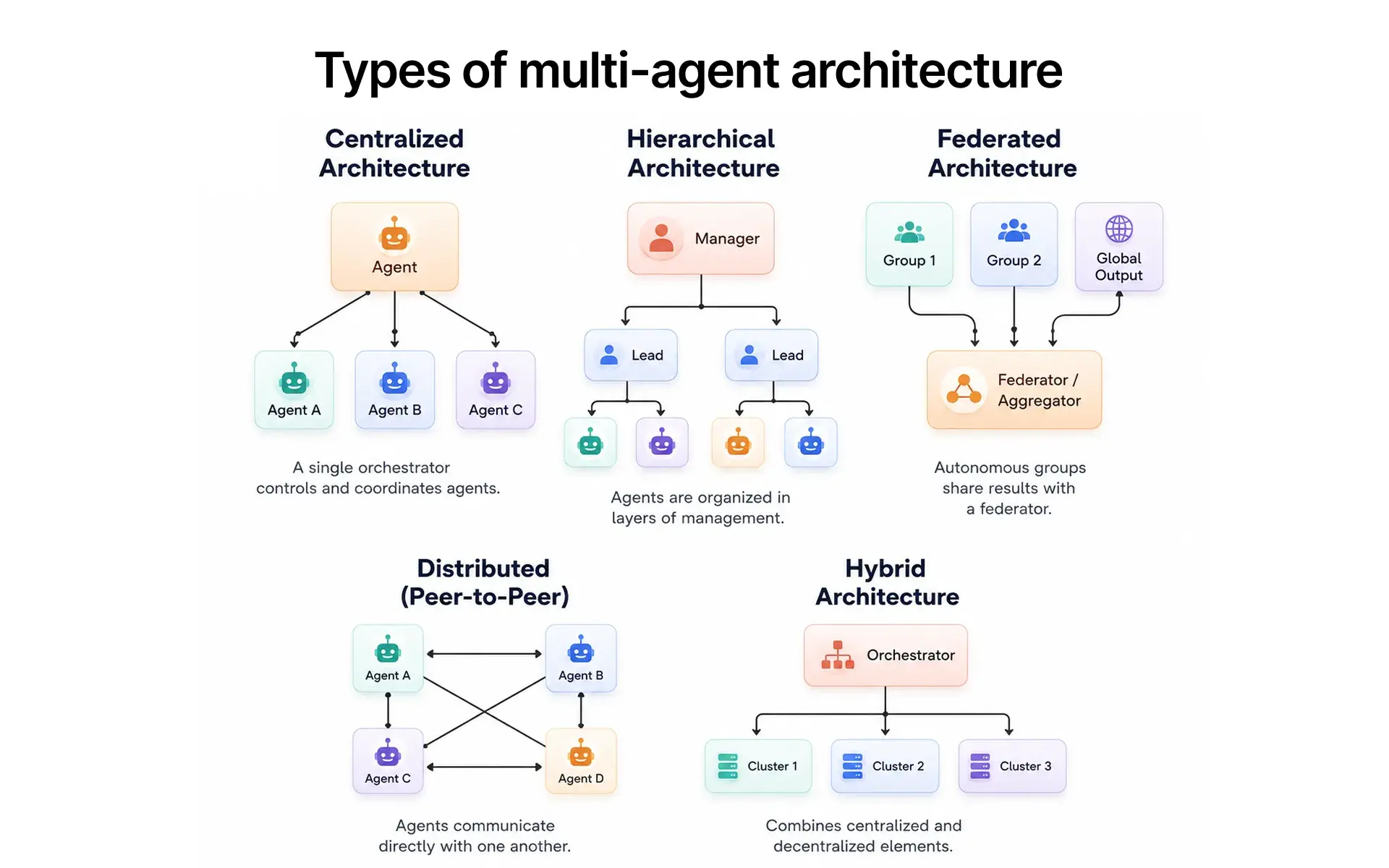
Choosing between orchestration patterns locks in your governance, observability, and scaling model from day one. There is no universally correct topology.
The centralised orchestrator-worker places a single orchestrator agent above specialised worker agents. The orchestrator decomposes tasks, makes API calls to downstream agents and external systems, collects outputs, arbitrates conflicts, and synthesises results. One point of control means one place to enforce access boundaries and log decisions - the governance-friendly default for regulated industries. The constraint: the orchestrator becomes a bottleneck under high task volume unless architected for stateless horizontal scaling from the start.
Peer-to-peer mesh lets agents communicate directly via defined communication protocols, including the Model Context Protocol (MCP) and the Agent2Agent (A2A) protocol, self-organising into task chains based on declared agent definitions and capabilities. This suits high-parallelism workloads and multi-framework stacks. The coordination risk: without strong protocol contracts, peer-to-peer systems produce non-deterministic execution paths and conflicting outputs.
Hierarchical multi-tier places a root orchestrator above mid-tier sub-orchestrators, each managing a domain cluster with its own discovery agent for intra-domain routing. This mirrors enterprise organisational structure and dominates large-scale deployments in financial services and healthcare. Domain-scoped audit trails and per-tier role-based access controls are the governance advantage. The cost is complexity: disciplined agent registries, inter-tier state contracts, and per-tier observability instrumentation before go-live.
Which one fits your team?
- Compliance-first or regulated data? Use a centralised orchestrator-worker.
- High-parallelism tasks across multiple frameworks? Use peer-to-peer mesh with strong protocol contracts.
- Complex domain-segmented enterprise workflows? Use a hierarchical multi-tier.
Our Take: Most teams default to the centralised pattern because it is easiest to reason about. That is defensible for the first deployment. The mistake is staying centralised at 50+ agents without building in stateless horizontal scaling for the orchestrator. We have seen this bottleneck stall production systems at the 3-month mark across logistics and financial services clients.
Framework Selection as an Architecture Decision
Framework selection is not about popularity. It is about which execution model matches your task topology, state requirements, and policy enforcement posture: state persistence model, model lock-in risk, observability hooks, and governance surface area.
AutoGen moved to maintenance mode in late 2025. Teams evaluating it for new builds should use Microsoft Agent Framework: policy-as-code orchestration, generative AI support, and full audit logging.
Should You Build Custom Orchestration or Use a Framework?
Use a framework when your agent topology is stable and coordination patterns are predictable. Build custom only when routing logic requires domain-specific guarantees that no framework can provide. A production-ready multi-agent platform with memory, tool use, security controls, and governance controls typically costs somewhere in the range of roughly £120K to £1.2M to build - a figure that reframes most build-versus-buy decisions.
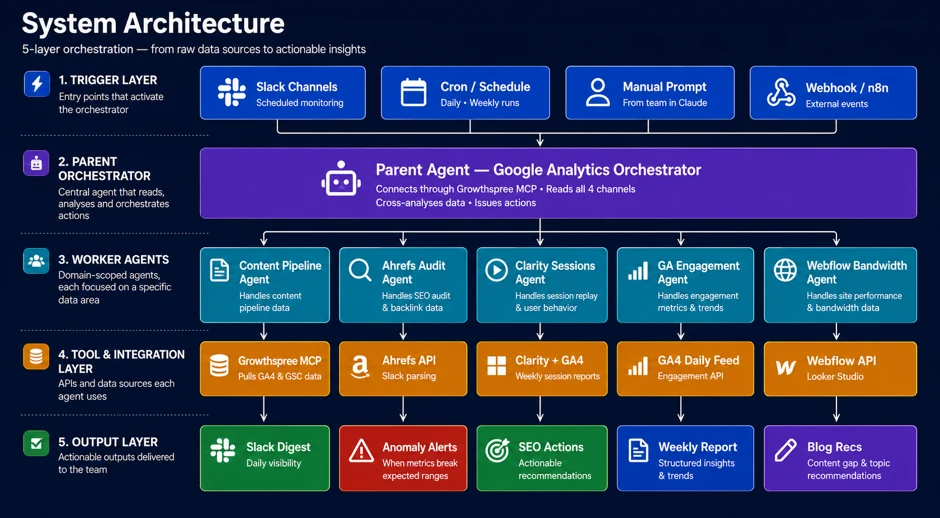
How BuildNexTech Built Its Own Google Analytics Orchestrator for the SEO Team
We didn't just advise clients on orchestration patterns. We ran the centralised orchestrator-worker model on our own SEO operation, because a five-person content and growth team can't manually reconcile GA4, GSC, Ahrefs, Clarity, and Webflow data every week and still ship. Here's how the system is structured, layer by layer.
- Trigger layer - The orchestrator activates from four entry points: scheduled Slack channel monitoring, cron-based daily and weekly runs, manual prompts from a team member working directly in Claude, and external webhooks via n8n. No single trigger type owns the system, which keeps the orchestrator usable both for scheduled reporting and ad hoc questions.
- Parent orchestrator - One agent sits above everything: the Google Analytics Orchestrator. It connects through a Growthspree MCP server, reads all four downstream channels, cross-analyses the data those channels surface, and issues actions back out. This is the single point of control we described earlier in this guide - one place to audit decisions, one place to enforce access boundaries.
- Domain-scoped worker agents - Below the parent sit five specialised agents, each mapped to its own Slack channel and its own data domain: Content Pipeline, Ahrefs Audit, Clarity Sessions, GA Engagement, and Webflow Bandwidth. Each worker only handles their slice of the problem. The content agent doesn't touch session-replay data, and the Ahrefs agent doesn't touch engagement metrics. That separation is what keeps routing precision high instead of overloading one agent with every tool.
- Tool and integration layer - Each worker agent calls a dedicated API or data source: the Growthspree MCP pulls GA4 and GSC data, the Ahrefs API feeds the audit agent via Slack parsing, Clarity and GA4 combine for weekly session reports, a GA4 Daily feed handles engagement, and the Webflow API connects through to Looker Studio. This is the schema-validated handoff layer in practice - each integration has one job and one output format.
- Output layer - The system closes the loop with five concrete outputs: a Slack digest for daily visibility, anomaly alerts when metrics break expected ranges, SEO action recommendations, a structured weekly report, and blog topic recommendations pulled from content gaps. None of these outputs requires a human to stitch together five different dashboards first.
The result isn't flashy, but it's the point: a five-channel data operation that used to take a person half a day to reconcile each week now runs as a standing system, with the parent orchestrator doing the cross-referencing a human analyst used to do manually. It's the same pattern we recommend to clients in this guide, just running on our own stack first.
Common Pitfalls in Enterprise Multi-Agent Orchestration
A healthcare network piloting agentic AI for patient intake discovered the failure at volume. At 40 concurrent customer service pipelines, inter-agent communication latency compounded, and two agents entered a dependency loop, which the monitoring setup caught only after 11 hours. Administrative burden increased, not decreased, until it was resolved.
Missing loop detection, not model hallucination, is what actually shuts down production systems. Multi-agent systems can enter circular dependency chains where Agent A waits for Agent B, which waits for Agent C, which is handed back to Agent A. Without explicit loop limits and a timeout-with-escalation path, the pipeline hangs indefinitely.
Shadow AI is the third pitfall: agents running outside the governed orchestration layer. One team in a 400-location retail environment had three separate engineering pods building agent workflows with no shared agent registry and no shared governance policies. Each worked alone. Together, they produced contradictory outputs in customer-facing systems. An agent registry with centralised capability metadata prevents this and is the foundation of any governed agentic orchestration system.

How BuildNexTech Accelerates Production-Ready Multi-Agent Orchestration
Most frameworks handle agent execution but leave the control plane - routing logic, state contracts, observability instrumentation, and governance policies enforcement - to the engineering team. That is where most agentic AI projects stall. BuildNexTech provides the full orchestration layer, not just the agent runtime.
Our AI automation services cover agent topology design, API integrations with existing enterprise systems, schema-validated handoff architecture, OTel instrumentation, and RBAC-based governance controls - without model lock-in. Teams move from pilot to production-ready in days, not months, by eliminating the infrastructure build that consumes 60%+ of agent project budgets before a single workflow runs.
What you own at the end: a documented agent topology with defined agent definitions, a fully instrumented orchestration layer, a fleet dashboard, and a governance package ready for SOC 2 review. A US hospital network reduced administrative burden by 40%; a logistics fleet achieved 30 to 50% downtime reduction; a retail chain auto-resolved 64% of IT tickets across 400 locations. In every case, the orchestration architecture - not the models - made the Artificial intelligence system safe at scale.
From Pilot to Production: What Disciplined AI Agent Orchestration Delivers
Most agentic AI projects do not fail because the agents are wrong. They fail because the system around the agents was never properly built. The teams that reach production treat AI agent orchestration as a first-class engineering problem: they define agent topologies and agent definitions before writing agent logic, instrument observability before running the first workflow, and enforce governance policies before testing at volume.
The result is a reliable Artificial intelligence system that auditors can review and compliance teams can sign off on. AI agent orchestration is not a framework selection problem. It is a systems design problem - and the teams solving it properly are building an operational advantage that gets harder to replicate as they scale.
People Also Ask

Q1. What is the difference between AI agent orchestration and workflow automation?
Workflow automation runs fixed steps. AI agent orchestration coordinates autonomous agents making their own routing decisions via natural language processing, API calls, and data pipelines - workflow tools cannot do this.
Q2. Which AI agent orchestration pattern should we choose?
Use a centralised orchestrator-worker for regulated environments, a peer-to-peer mesh for high-parallelism stacks, and hierarchical multi-tier for complex domain-segmented enterprise workflows. Base the choice on governance requirements, not framework convenience.
Q3. How do we prevent a hallucinated output from one agent from corrupting the entire pipeline?
Implement schema-validated handoffs at every agent boundary. The orchestration layer validates each output before routing downstream; if validation fails, it triggers error handling - retry, escalate, or halt.
Q4. What is the minimum observability setup before going live with a multi-agent system?
Four layers: per-run structured logging with API calls and reasoning traces, schema-validated output capture, a governance record for SOC 2, and a fleet dashboard with a monitoring and feedback loop.
Q5. When should we build custom orchestration instead of using a framework?
Use a framework when coordination patterns are stable. Build custom only when routing logic requires security controls, and governance controls no framework can provide - builds cost £120K to £1.2M.





.webp)
.webp)
.webp)

