


During the AI revolution, transformer models have become the foundation of modern natural language processing and multimodal applications. Hugging Face, as a major player in this space, provided tools, pre-trained models, and frameworks with which to develop AI and deliver at scale AI ML development services or enterprise AI development services. This technical guide provides an overview of how Hugging Face Transformers function, their architecture and ecosystem, and their use for AI application development services.
- Hugging Face Transformers Eco System — Key components comprising the Transformers library, Tokenizers, and Model Hub.
- Digging into some Transformer Architecture — Learn how an Encoder-Decoder with Self-Attention powers large language models.
- Hugging Face Pipelines: From the implementation in practice — Get an overview on creating and deploying NLP and multimodal AI applications.
- Real-World Industry Applications: Showing the Usage of Hugging Face Models — Observation on how healthcare, finance, and other sectors have taken full advantage of Hugging Face models.
- Hugging Face Open Source and Business Ecosystem — Know about the community spirit-driven innovation and business value to AI development services.

Hugging Face AI and Its Role in NLP Machine Learning
Hugging Face unveils a whole new world in using pre-trained models and pipelines for natural language processing, image, and multimodal tasks, which let creators make AI apps like chatbots, translate, and process images with almost no custom training. Their Hub provides a vast selection of models for straightforward inference, and a robust community stands behind it with tutorials and library enhancements.
Deep Dive into the Hugging Face Transformers Library
The Hugging Face Transformers Library is designed to abstract away complex architectures. It allows a developer to accomplish NLP tasks easily, perform inference with text generation, or enable multi-modal capabilities. It integrates smoothly with PyTorch, TensorFlow, and JAX and has support for Google Colab, virtual environment, and enterprise-level deployments on NVIDIA A10G GPUs (or Databricks Runtime).
Core Functionalities and Advanced Features of the Transformers Framework
The Transformers Framework from Hugging Face is a great platform for developing, training, and deploying cutting-edge deep learning models for different types of data, like text, image, and speech. The architecture focuses on the aspects of modularity, scalability, and integration into AI development pipelines.
Key functionalities include:
- Auto Classes: Automatically load configurations using AutoModel or AutoTokenizer
- Pipelines: For tasks that can be used out of the box, such as sentiment analysis, a question answering system, or a question answering system on documents.
- Trainer API: To fine-tune a model on a custom dataset.
- Compatibility: HuggingFace vector databases, ONNX, multimodal applications (such as Stable Diffusion or Speech T5).
Code example: Basic Text Classification Pipeline
from transformers import pipeline
classifier = pipeline("text-classification")
result = classifier("Hugging Face Transformers enable fast AI development services.")
print(result)A very basic text classification is accomplished by this code through the use of a Hugging Face pre-trained model.
- It imports the pipeline function from the Transformers library.
- The pipeline("text-classification") is an automated process that brings a pre-trained model ready for use.
- The text "Hugging Face Transformers enable fast AI development services" is input into the model for processing.
- The model produces a tag (for example, POSITIVE or NEGATIVE) and a trust level.
- In the end, print(result) shows the result.
Transformer Architecture as the Backbone of Large Language Models (LLMs)
Each Hugging Face model is based on the LLM transformer architecture, which consists of an encoder-decoder architecture, attention masks, and embedding layers. It is with this design that models can process sequences of tokens in parallel, typically utilizing token IDs in text generation inference models, translation applications, etc.
Architecture and Mechanisms of Transformer Models
Transformers have a highly efficient way of managing sequential data, such as text, by means of three vital components: among them is self-attention which allows the model to assess relationships among all the tokens at once; alongside embedding layers that transmute inputs into meaningful dense vectors to help understand the context; and finally, there is the encoder-decoder structure where the encoder does the input processing and the decoder performs the output generation thereby making it possible to widely apply NLP as well as multimodal applications.
The Foundational LLM Transformer Architecture Explained
The architecture of a Transformer is based on three fundamental components. These components are:
Encoder: Generates input tokens in contextually relevant embedding.
Decoder: Generates sequences for output words based on the input sequences and attention.
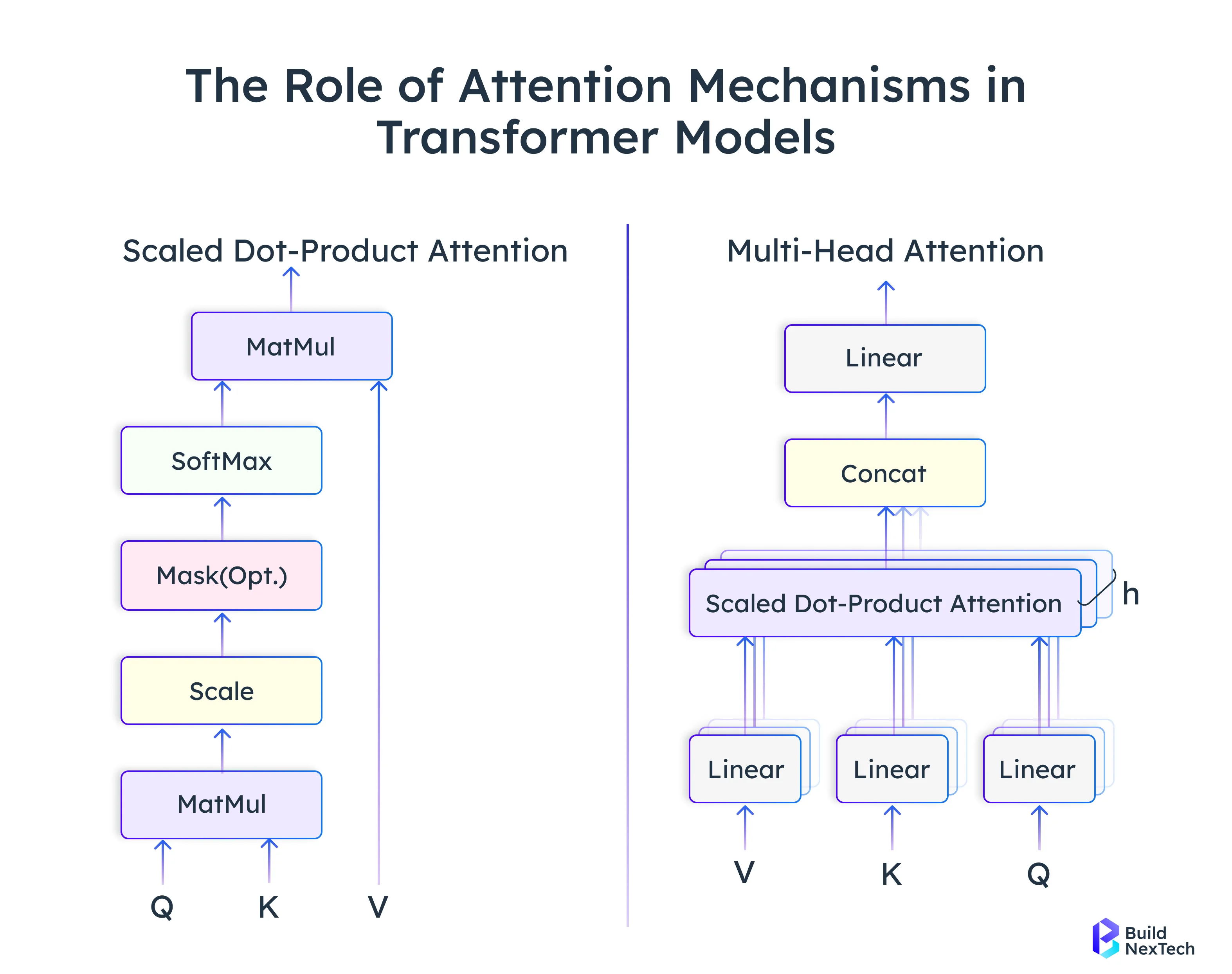
Attention Mechanism: Calculates relevance of tokens via:
Attention(Q, K, V) = softmax(Q K^{T} / \sqrt{d_k}) V
Code Example: Load an Encoder-based Model
from transformers import AutoModel
model = AutoModel.from_pretrained("bert-base-uncased")
print(model.config.architectures)- from transformers import AutoModel → Importazione della classe AutoModel per il caricamento dei modelli pre-addestrati.
- AutoModel.from_pretrained("bert-base-uncased") → Caricamento del modello BERT con pesi pre-addestrati.
- print(model.config.architectures) → Mostra l'architettura del modello caricato.
- This code helps you quickly load and inspect an encoder-based transformer model for NLP tasks.
Internal Operations – Self-Attention, Tokenization, and Model Optimization
- Self-Attention
By using self-attention, AI models can grasp the contextual relationships between the input data and, at the same time, determine the importance of each token in relation to the others in the sequence. Thus, such a mechanism allows models to concentrate on the most pertinent information, thus improving the quality of the understanding, coherence, and overall performance in NLP, vision, and multimodal tasks.
- Tokenization
Tokenization is the process of changing the raw text into numerical token IDs for further processing by the model. It specifies the language granularity - word, subword, or character level - which influences the model's accuracy, inference speed, and adaptability. Solid tokenization guarantees the uniformity of the interpretation of linguistic patterns in multilingual and domain-specific applications.
- Model Optimization
Model optimization is the process of refining performance through the implementation of efficient training loops, validation, and self-supervised learning. It supports the deployment of AI models that are scalable, robust, and accurate by tuning parameters and minimizing loss functions.
Implementation Efficiency within Hugging Face Transformer Pipelines
The optimization and deployment strategies advanced to improve the performance and scalability are the miraculous ways through which Hugging Face Transformer Pipelines gain their efficiency.
- Mixed-Precision Training (FP16): It is the process that accelerates the computation, reduces the memory usage, and yet keeps the model's accuracy.
- ONNX & TorchScript Exports: They are the means to inferencing that is faster and cross-platform deployment by the execution of the optimized model graph.
- Parallel Processing on NVIDIA A10G GPUs: Such a technique not only boosts the throughput but also allows large-scale workloads to be handled through distributed training.
- Vector Database Integration: It is a method that makes the embedding-based similarity search for such applications as RAG and semantic retrieval very quick and efficient.
- Flexible Execution Environments: These are the environments that can run on various virtual and cloud platforms, such as Google Colab and Databricks Runtime, and hence the workflows are scalable and collaborative.
The Hugging Face Ecosystem: Corporate and Open-Source
Hugging Face occupies the intersection of community and business—combining a rich open-source foundation (Transformers, Diffusers, Datasets, Spaces) with production-scale services such as the Model Hub, Inference Endpoints, and TGI. Teams can prototype rapidly using community models, then scale to secure, compliant product deployments without having to change ecosystems. The outcome is one platform where research, collaboration, and practical ML delivery converge.
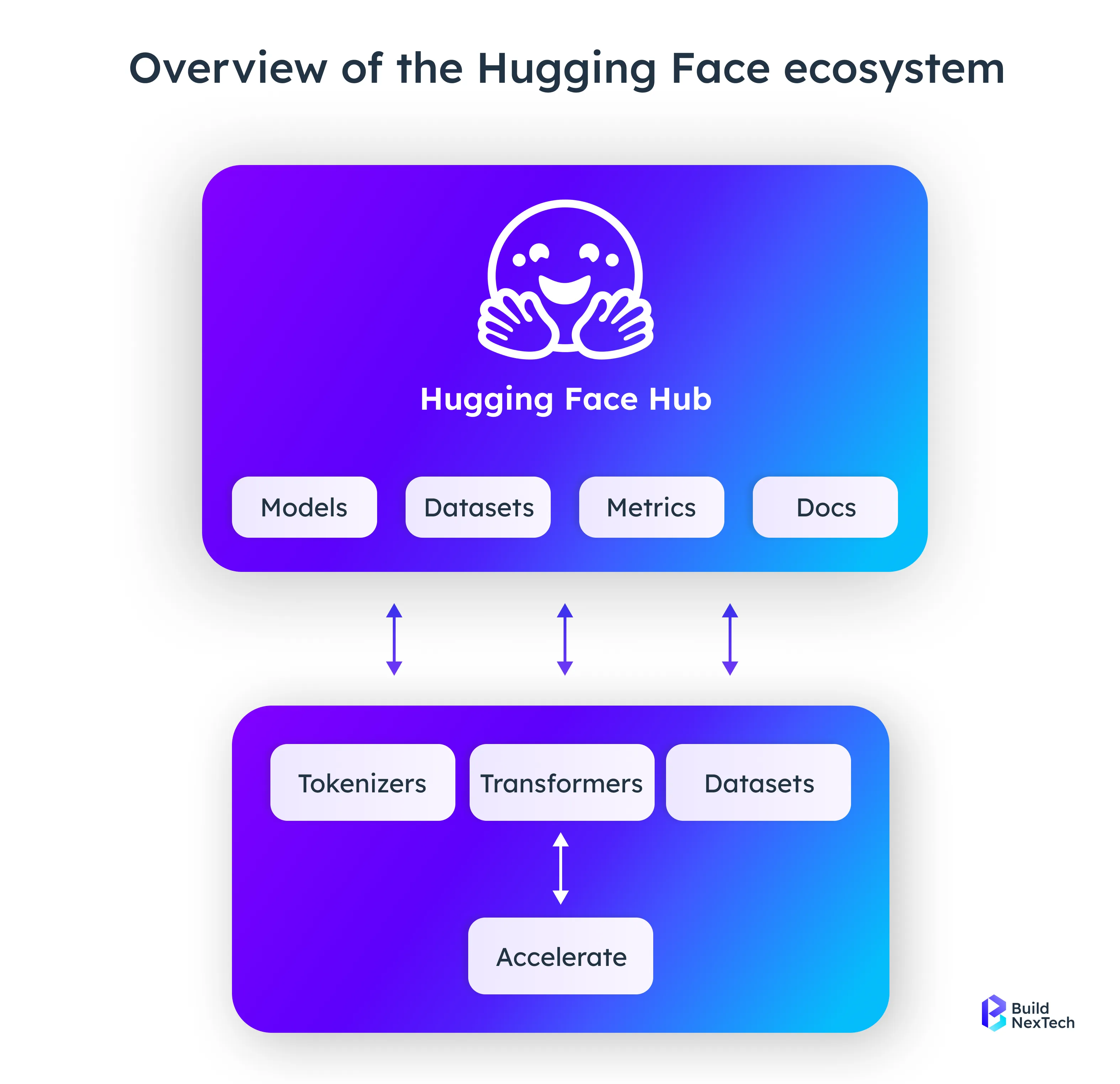
Hugging Face can be looked upon as the meeting point between open-source innovation and enterprise-scale solutions; it provides a seamless and single platform around research, collaboration, and production-scale deployment, thus eliminating any issues of incompatibility.
Open-Source Foundation
The ecosystem's backbone is made up of very robust open-source libraries: Transformers, Diffusers, Datasets, and Spaces. These libraries can be used to very quickly prototype, fine-tune pretrained models, and even conduct research in the areas of natural language processing, vision, and multimodal tasks — all using one straightforward and user-friendly, plus developer-friendly environment.
Enterprise-Grade Infrastructure
Hugging Face comes with several scalable services for companies that are going to move from research to production, which include:
- Model Hub – a centralized repository for models and datasets
- Inference Endpoints – managed APIs for secure and low-latency model deployment
- Text Generation Inference (TGI) – infrastructure designed for serving large language models
With these layers, a complete AI ecosystem is formed, which allows the teams to perform their testing with the community resources and still be able to transition to secure, compliant, production-ready deployments without platform-switching.
Applied Use Cases and Industry Implementations
The Hugging Face Transformers multifaceted capability not only benefits the research domain but also wraps the real-world applications up to and including the most varied industries. Healthcare-related analytics and financial regulations are just some examples of enterprises that utilize pre-trained models, fine-tuning, and inference scalability for automation, insight production, and cost-effectiveness. Below are the main areas of application where these models are already changing the process significantly.
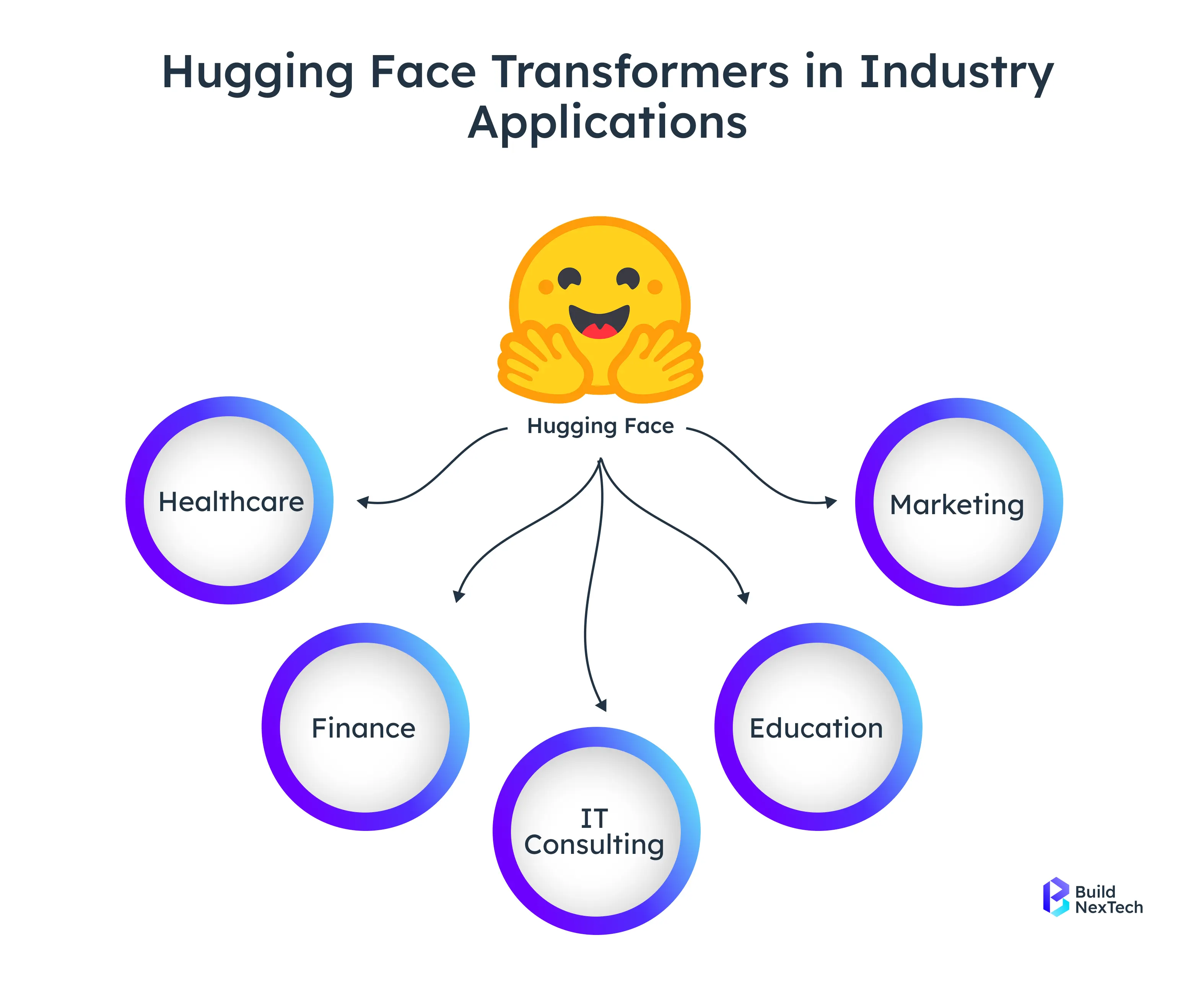
1. Healthcare: Clinical NLP and De-identification
Transformers—that is, go on extracting clinical data, automating the generation of reports, and giving full assurance to the privacy of patients. BioBERT or ClinicalBERT-like models demarcate medical entities, which in turn feed into de-identification pipelines that take out PHI but at the same time maintain context for safe research data sharing.
2. Finance: Risk Scoring and KYC Automation
Transformers, to mention one example, FinBERT, look over the financial news for risk scoring and also automate the KYC processes by verifying documents, extracting entities, and ensuring compliance, all of which are done quickly because the manual review time has been cut down.
3. Education: Learning Analytics and Content Summarization
When T5 or BART are used for summarization of academic content, quiz generation, and the adaptation of study materials, then learning becomes more individualized and friendly because of the automated language-adaptive tools.
4. Marketing: Campaign Insights and Customer Sentiment
Through the use of DistilBERT, marketing teams are allowed to be notified about audience sentiment on social media instantly, and consequently, they can open up channels for data-driven campaigns, improved engagement, and better brand management.
5. IT Consulting: Automation and AI Integration
Hugging Face Transformers are the backbone of large-scale enterprise workflows such as document summarization, chatbots, and RAG; thus, they are the ones who speed up the digital transformation, support faster prototyping, and make sure that AI deployment is done in a scalable manner.
Conclusion
Hugging Face Transformers have transformed the AI software development services, AI ML development services, and AI application development services marketplace. Hugging Face provides a wealth of pre-trained models, an encoder-decoder architecture, multi-modal applications, and optimized model inference, allowing developers and AI consulting services companies to develop AI solutions in a robust, scalable, and efficient way.
Furthermore, with organizational support, Google Colab, Databricks Runtime, and NVIDIA A10G, we can experiment with vision language models, image captioning, translation applications, or question answering systems easily. The combination of open-source innovation with enterprise-ready tools ensures Hugging Face will remain at the forefront of the AI and ML software development services across the globe.
People Also Ask

How is a transformer different from RNNs or LSTMs?
Transformers employ self-attention to be able to grasp interactions over the entire sequence, whereas RNNs/LSTMs rec
What are some popular transformer models available on Hugging Face?
BERT, GPT, T5, ViT, and Speech T5 are used for text generation, image classification, and audio processing.
What is the Vision Transformer (ViT) in Hugging Face?
ViT splits the image into patches, treats them as tokens, and carries out image classification and image captioning.
What are the main applications of Hugging Face Transformers?
These are being used for text classification, machine translation, question-answering systems, and image captioning.
How are Hugging Face Transformers different from GPT or ChatGPT?
Hugging Face provides a library ecosystem with multiple pre-trained models, while GPT/ChatGPT are specialized text generation implementations.





.webp)
.webp)
.webp)

