


In our current data-centric world, companies are producing enormous volumes of information at unprecedented rates. However, many organizations find themselves overwhelmed, unable to process and analyze this data fast enough to gain meaningful insights. The challenge lies not just in collecting data, but in transforming it into actionable intelligence that can drive immediate business decisions. Traditional data processing methods often fall short when speed and agility are paramount for maintaining market position. Organizations that fail to adapt their data infrastructure risk falling behind competitors who can respond to market changes in real-time. The ability to build and maintain efficient data pipelines for instant analytics has emerged as a game-changing differentiator. Companies that master this capability can identify trends, respond to customer needs, and capitalize on opportunities faster than ever before. This technological advantage has become the defining factor that separates market leaders from those struggling to keep pace in today's competitive landscape.
💡Here are the key insights from this article
📌 Understand streaming vs batch processing architectures.
📌 Master core pipeline components: ingestion, processing, and storage.
📌 Explore Apache Kafka for scalable real-time data systems.
📌 Learn strategies for handling latency, throughput, and fault tolerance.
📌 Apply design principles balancing performance, reliability, and maintainability.
This comprehensive guide will equip you with the knowledge to transform your organization's data processing capabilities and unlock the power of real-time analytics for immediate business impact.
What is a Data Pipeline?
A data pipeline is a series of automated processes. These processes move data from various Data Sources through data transformation steps to a final destination. Think of it as a sophisticated assembly line for data processing. Each stage adds value by cleaning, enriching, transforming, or aggregating information through data ingestion and processing layers.
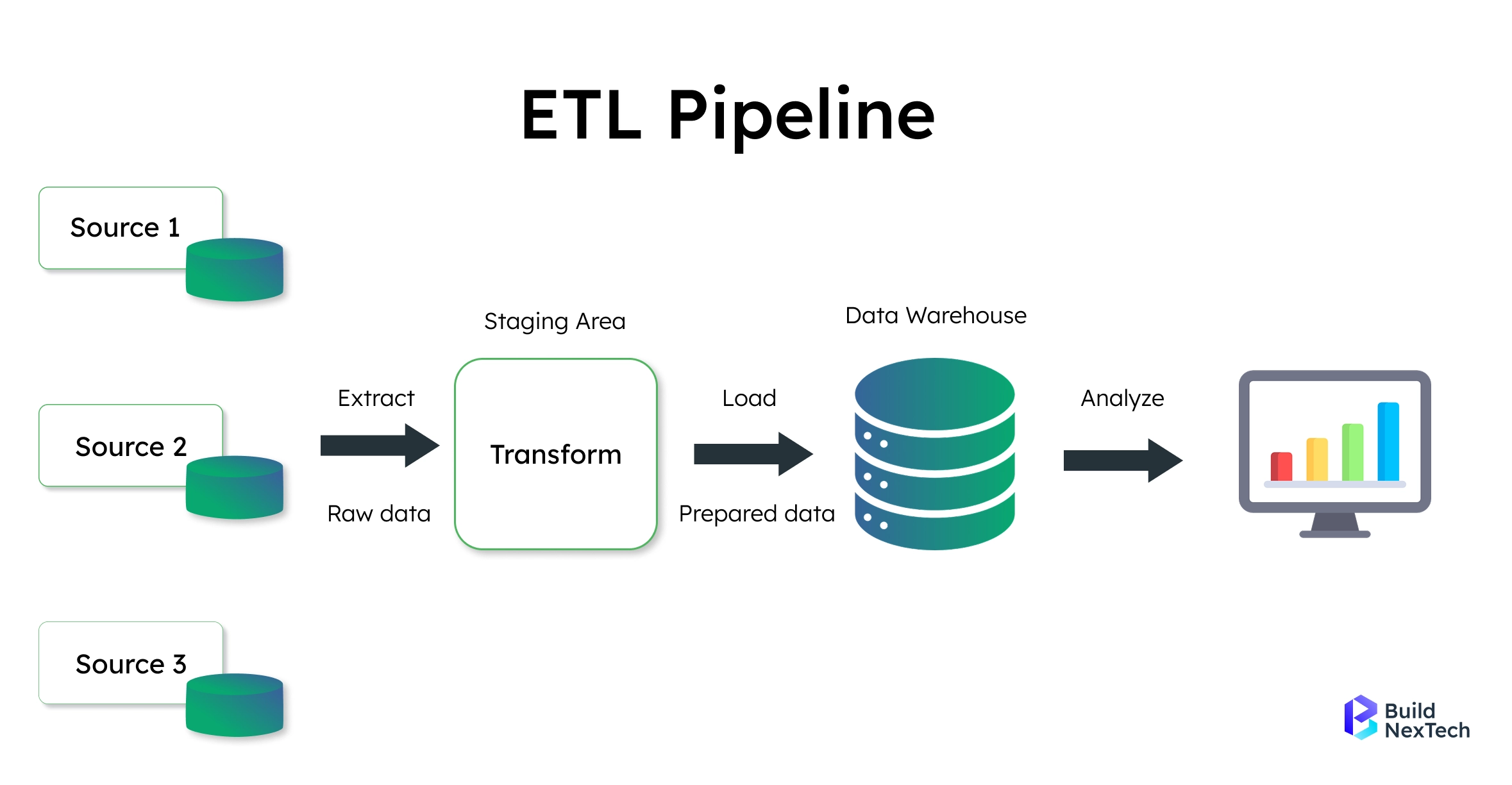
Modern data pipelines serve as the backbone of data engineering infrastructure. They help organizations:
- Automate data flow from multiple Data Sources to centralized data warehouse systems
- Ensure data quality through validation and cleansing processes using specialized data quality tools
- Transform data into analysis-ready formats through sophisticated data transformation logic
- Scale processing using scalability principles to handle growing data volumes across cloud platforms
- Maintain data integrity and consistency across different systems
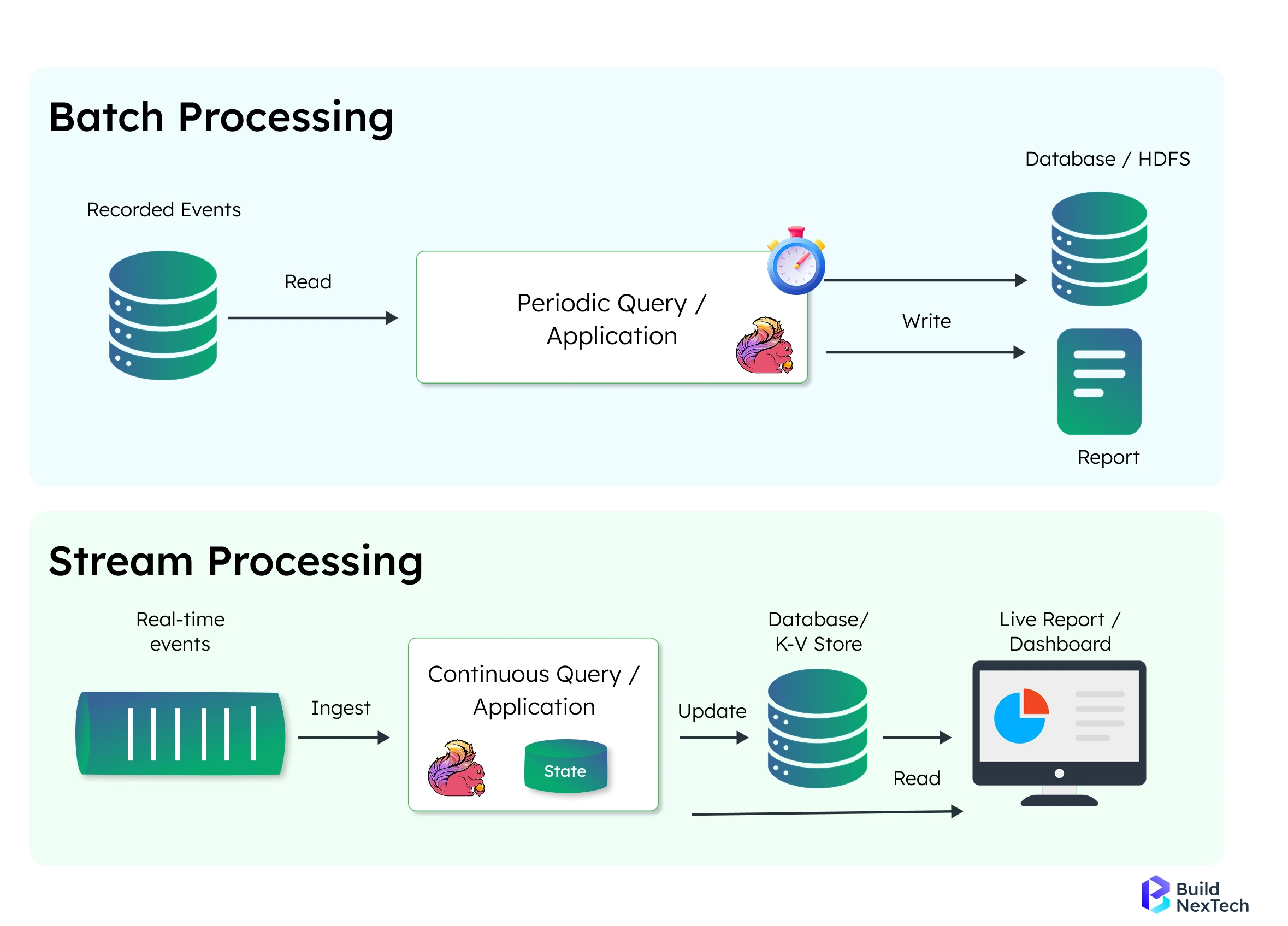
Real-Time Analytics vs Batch Processing
The choice between real-time data and batch processing shapes your data pipeline architecture. Each approach serves different business needs. They also come with distinct trade-offs in terms of latency, complexity, and resource requirements.
Key Differences Between Real-Time and Batch
Real-time and batch processing represent two fundamental approaches to handling data, each with distinct characteristics and optimal use cases. Understanding their differences is crucial for selecting the right architecture for your specific business needs.
The choice between real-time and batch processing ultimately depends on your organization's specific requirements, budget constraints, and the urgency of insights needed. Many modern data architectures implement hybrid approaches, combining both methods to maximize efficiency and meet diverse analytical needs.
When to Use Each Approach
Use real-time data processing for
- Financial services requiring immediate fraud detection and risk assessment through real-time data analysis
- E-commerce platforms delivering personalized recommendations based on current user interactions
- IoT monitoring applications monitoring critical systems and triggering automated responses
- Social media platforms providing instant user interactions and notifications
Use batch processing for
- Data warehouse operations involving large-scale aggregations and historical analysis
- Machine learning model training requiring comprehensive datasets and predictive analytics
- Business Intelligence reporting with specific timing requirements
- Data storage and archival processes where data integrity matters more than speed
Core Components of an Efficient Data Pipeline
Building robust data pipelines requires understanding the fundamental components. These components ensure reliable, scalable, and maintainable data processing across streaming platforms and cloud platforms.
Data Ingestion
The data ingestion layer serves as the entry point for all data entering your pipeline. This component must handle diverse Data Sources including:
- Databases
- APIs
- File systems
- Message queues
- Streaming platforms
Effective data ingestion strategies account for different data formats, volumes, and delivery patterns while maintaining data quality.
Push vs Pull Mechanisms
Modern data ingestion systems support both push and pull mechanisms.
Push-based ingestion receives data as it becomes available. This is ideal for streaming scenarios where external systems send data through Apache Kafka.
Pull-based ingestion actively retrieves data from sources on a scheduled basis. This suits batch processing workflows managed by orchestration tools.
Key Considerations
Important considerations include:
- Schema evolution handling
- Backpressure management
- Data validation at entry points
- Monitoring Framework integration with Metrics and Logs for detecting failures
Processing Layer (Stream or Batch)
The processing layer transforms raw data into valuable insights. It handles filtering, aggregation, enrichment, and computation.
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
# -----------------------------
# Initialize Spark session
# Enable Adaptive Query Execution for optimization
# -----------------------------
spark = SparkSession.builder \
.appName("DataPipelineBatch") \
.config("spark.sql.adaptive.enabled", "true") \
.getOrCreate()
# -----------------------------
# Define expected schema for input JSON
# -----------------------------
dataschema = StructType([
StructField("user_id", IntegerType(), True),
StructField("timestamp", TimestampType(), True),
StructField("event_type", StringType(), True),
StructField("amount", DoubleType(), True)
])
# -----------------------------
# ETL Function: process one day's batch
# -----------------------------
def process_daily_batch(input_path: str, output_path: str):
# Extract: Read raw JSON data using predefined schema
df = spark.read.schema(dataschema).json(input_path)
# Transform: Add date column, group, and aggregate
processed_df = df \
.withColumn("date", date_format("timestamp", "yyyy-MM-dd")) \
.groupBy("user_id", "date", "event_type") \
.agg(
sum("amount").alias("total_amount"),
count("*").alias("event_count"),
max("timestamp").alias("last_event_time")
) \
.filter(col("total_amount") > 0) # Filter out non-positive totals
# Load: Write as Parquet files partitioned by date
processed_df.write \
.mode("overwrite") \
.partitionBy("date") \
.parquet(output_path)
return processed_df
# -----------------------------
# Run the ETL pipeline for today's batch
# -----------------------------
result = process_daily_batch("s3://raw-data/", "s3://processed-data/")
# Show sample of processed data
result.show()
Real-time data pipelines process data in motion through in-memory computations. They use tools called stream processing frameworks such as Apache Kafka Streams, Apache Flink, and Apache Spark Streaming.
Batch processing layers operate on data at rest. They leverage distributed computing frameworks like Apache Spark to process large datasets efficiently. Technologies like AWS Glue and Google BigQuery provide computational power for complex data transformation operations.
Processing Layer Requirements
The processing layer must handle:
- Data transformation including format conversion and field mapping
- Business logic implementation for calculations and derived Metrics
- Error handling and recovery mechanisms
- State management for maintaining context across processing steps
Storage & Query Layer
The Data storage and query layer provides durable persistence for processed data. It enables efficient retrieval for downstream consumers.
Modern storage architectures employ data lake approaches. They store raw and processed data in cost-effective object storage while maintaining metadata catalogs.
Data warehouse solutions like Snowflake and Google BigQuery provide structured storage optimized for analytical queries. Specialized systems offer high-performance access for real-time data applications.
Storage Considerations
Key considerations include:
- Data partitioning strategies
- Compression and encoding
- Indexing for fast retrieval
- Security protocols
- Backup for business continuity
Understanding ETL in Modern Pipelines
Extract, Transform, Load (ETL pipeline) remains fundamental in data engineering. However, implementation has evolved with modern technologies.
Traditional ETL pipeline processes followed rigid sequences. Modern systems adopt flexible patterns like:
- ELT leveraging cloud data warehouses
- Streaming ETL through Apache Kafka
- Micro-batch processing combining both paradigms
Data Transformation Requirements
The data transformation layer must handle:
- Data quality validation using data quality tools
- Schema evolution enforcement supporting Slowly Changing Dimensions
- Data lineage tracking for governance
- Performance optimization to minimize latency
from confluent_kafka.schema_registry import SchemaRegistryClient
from fastavro import parse_schema, validate
import logging
logging.basicConfig(level=logging.INFO)
# Initialize Schema Registry client
schema_registry_client = SchemaRegistryClient({'url': 'http://localhost:8081'})
# Define latest Avro schema (v2)
user_schema_v2 = {
"type": "record",
"name": "User",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "email", "type": "string"},
{"name": "phone", "type": ["null", "string"], "default": None} # New optional field
]
}
parsed_schema_v2 = parse_schema(user_schema_v2)
def handle_schema_evolution(msg: dict, version: int) -> dict | None:
"""
Handle backward-compatible schema changes and validate message
"""
if version == 1:
msg['phone'] = None # Add default for new field
return msg if validate(msg, parsed_schema_v2) else None # Validate against latest schema
# Example usage
msg_v1 = {'id': 1, 'name': 'Alice', 'email': 'alice@example.com'}
validated_msg = handle_schema_evolution(msg_v1, version=1)
logging.info(f"Validated message: {validated_msg}")
Apache Kafka: The Backbone of Real-Time Pipelines
Apache Kafka's architecture centers around a distributed commit log. This enables multiple producers to write data and consumers to read concurrently.
from kafka import KafkaProducer
import json
import time
import logging
# -----------------------------
# Configure logging
# -----------------------------
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# -----------------------------
# Initialize Kafka producer
# -----------------------------
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
key_serializer=lambda k: str(k).encode('utf-8'),
retries=5 # Retry sending if failed
)
# -----------------------------
# Function to ingest user events
# -----------------------------
def ingest_user_events(user_id: int, event_data: dict, topic: str = 'user-events'):
"""
Sends a user event to Kafka.
Args:
user_id (int): Unique user identifier
event_data (dict): Event details (e.g., action, amount)
topic (str): Kafka topic to send the message to
"""
try:
event_payload = {
'user_id': user_id,
'timestamp': int(time.time()),
'event': event_data
}
producer.send(topic=topic, key=user_id, value=event_payload)
producer.flush()
logging.info(f"Event sent successfully for user {user_id}")
except Exception as e:
logging.error(f"Error sending event for user {user_id}: {e}")
# -----------------------------
# Example usage
# -----------------------------
if __name__ == "__main__":
ingest_user_events(12345, {'action': 'purchase', 'amount': 99.99})
Core components include:
- Producers: Publishing data through APIs
- Topics: Serving as logical channels for data flow
- Partitions: Enabling parallel processing and scalability
- Consumers: Processing real-time data streams
- Brokers: Storing and serving data with fault tolerance
Confluent Kafka
Apache Kafka gives the basic tools for streaming data, but Confluent Kafka adds more features that are useful for big companies.
- Schema registry for schema evolution management
- Monitoring Framework with dashboards and Metrics
- Security protocols enhancements
- Multi-datacenter replication for disaster recovery
AWS Data Pipeline: Cloud-Native Orchestration
Amazon Web Services offers comprehensive tools for building data pipelines in the cloud. AWS Glue serves as managed orchestration tools. It automates movement and data transformation between AWS services and on-premises Data Sources.
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
# -----------------------------
# Initialize Glue context
# -----------------------------
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# -----------------------------
# Read data from Glue Data Catalog
# -----------------------------
datasource = glueContext.create_dynamic_frame.from_catalog(
database="analytics_db",
table_name="raw_events"
)
# -----------------------------
# Apply transformations
# -----------------------------
mapped_data = ApplyMapping.apply(
frame=datasource,
mappings=[
("user_id", "string", "user_id", "int"),
("event_timestamp", "string", "event_timestamp", "timestamp"),
("event_data", "string", "event_data", "string"),
("amount", "string", "amount", "double")
]
)
# -----------------------------
# Filter and clean data
# -----------------------------
filtered_data = Filter.apply(
frame=mapped_data,
f=lambda x: x["amount"] is not None and x["amount"] > 0
)
# -----------------------------
# Write processed data to S3 in Parquet format
# -----------------------------
glueContext.write_dynamic_frame.from_options(
frame=filtered_data,
connection_type="s3",
connection_options={
"path": "s3://processed-bucket/daily-aggregates/"
},
format="parquet"
)
# -----------------------------
# Commit Glue job
# -----------------------------
job.commit()AWS Glue Features
AWS Glue provides:
- Visual pipeline designers
- Automatic retry and failure handling
- Flexible scheduling through orchestration tools
- Monitoring Framework through CloudWatch with Metrics
- Security protocols through IAM roles
Real-Time Processing with AWS
For real-time data processing, AWS offers:
- Amazon Kinesis Data Streams
- AWS Kinesis Data Firehose
- Amazon Kinesis Analytics
These services work together to create streaming data pipelines handling high-velocity data flow.
Challenges in Building Real-Time Data Pipelines
Creating good real-time data processing systems is tricky. They need smart solutions to handle data as it comes in constantly.
Latency and Throughput Issues
Real-time data processing systems must balance low latency and high throughput. Common challenges include:
- Network delays between distributed components
- Serialization overhead when passing data using JSON formats
- Garbage collection pauses in streaming applications
- Resource contention during peak periods
Optimization Strategies
Effective optimization strategies include:
- Parallel processing through scalability and partitioning across Apache Kafka topics
- Batch micro-aggregation reducing per-event overhead
- Memory optimization minimizing garbage collection impact
- Efficient data structures for state management
Fault Tolerance & Retry Mechanisms
Streaming systems must handle failures gracefully without losing data or duplicating processing. Critical considerations include:
- Exactly-once processing guarantees
- State management and recovery after failures
- Checkpoint mechanisms for resuming from known states
- Dead letter queues for unprocessable messages
Retry Strategies
Retry strategies balance reliability with performance through:
- Exponential backoff
- Circuit breakers preventing cascading failures
- Timeout management avoiding blocking
- Monitoring Framework with alerting using Metrics and Logs
import time
import logging
from functools import wraps
# -----------------------------
# Custom exception for retryable errors
# -----------------------------
class RetryableError(Exception):
pass
# -----------------------------
# Retry decorator with exponential backoff
# -----------------------------
def retry_with_backoff(max_retries=3, backoff_factor=2, max_delay=60):
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
delay = 1
for attempt in range(max_retries + 1):
try:
return func(*args, **kwargs)
except RetryableError as e:
if attempt == max_retries:
logging.error(f"Max retries exceeded for {func.__name__}: {e}")
raise
wait_time = min(delay, max_delay)
logging.warning(f"Attempt {attempt + 1} failed, retrying in {wait_time}s: {e}")
time.sleep(wait_time)
delay *= backoff_factor
except Exception as e:
logging.error(f"Non-retryable error in {func.__name__}: {e}")
raise
return None
return wrapper
return decorator
# -----------------------------
# Example usage: process a data batch
# -----------------------------
@retry_with_backoff(max_retries=3, backoff_factor=2)
def process_data_batch(batch_data):
if not batch_data:
raise RetryableError("Empty batch received")
try:
# Simulate database connection failure
# raise ConnectionError("DB connection lost") # Example
processed_count = len(batch_data)
logging.info(f"Successfully processed {processed_count} records")
return processed_count
except ConnectionError:
raise RetryableError("Database connection failed")
except ValueError as e:
# Non-retryable error
raise e
# -----------------------------
# Dead Letter Queue (DLQ) sender
# -----------------------------
def send_to_dlq(failed_message, error_info, producer):
"""
Send failed messages to a DLQ (Kafka, SQS, etc.)
"""
dlq_message = {
'original_message': failed_message,
'error': str(error_info),
'timestamp': int(time.time()),
'retry_count': getattr(failed_message, 'retry_count', 0)
}
producer.send('dead-letter-queue', value=dlq_message)
Industry Use Cases
Real-world applications demonstrate the practical value of well-designed streaming and batch processing systems across industries.
Fintech – Real-Time Fraud Detection
Financial services companies rely on streaming data pipelines to detect fraudulent transactions within milliseconds. These systems analyze transaction patterns and user interactions to identify suspicious activities.
They leverage real-time data analysis and machine learning algorithms for adaptive detection while maintaining customer experience.
E-commerce – Live Personalization
Online retailers use streaming data pipelines to deliver personalized experiences based on real-time data from user interactions. Systems process clickstream data and purchase history to provide relevant recommendations.
This helps customers feel better and pushes the change to digital using predictions and data analysis.
Healthcare & IoT – Monitoring & Alerts
Healthcare providers and IoT monitoring setups depend on streaming data pipelines to keep track of essential systems. Key features include:
- Edge computing integration enabling local processing reducing latency
- Bandwidth optimization through filtering
- Offline operation capabilities
- Security protocols enhancement through data localization
Advanced Technologies and Future Trends
Modern data pipeline implementations increasingly leverage advanced technologies including:
- Containerization
- Kubernetes for orchestration tools
- Serverless computing for event-driven processing
- Microservices architecture enabling independent scaling
Edge Computing Impact
Edge computing is transforming real-time data processing by bringing computation closer to Data Sources. 5G networks enable new possibilities for IoT monitoring applications.
Machine learning integration through AutoML and federated learning enables more intelligent processing and decision-making.
Data Governance Requirements
Data governance requirements drive comprehensive data lineage tracking and metadata management. Advanced governance includes:
- Automated lineage tracking
- Schema evolution management
- Data catalog integration
- Compliance automation for regulatory requirements
Vendor Solutions and Platform Selection
The data engineering ecosystem includes numerous vendor solution options. Specialized platforms like Coalesce for data transformation, SuperAGI for AI-powered optimization, and custom-built pipelines offer different advantages.
Selection Criteria
Consider these factors when selecting solutions:
- Technical requirements
- Scalability needs
- Integration with existing analytics tools
- Budget constraints
- Team expertise
Hybrid Implementation Strategies
Hybrid implementation strategies often provide optimal balance. They combine:
- Apache Kafka is used for building streaming systems and works with cloud platforms that offer managed services.
- Apache Spark for processing with vendor solution tools for orchestration
- Multi-cloud approaches for vendor diversification
Conclusion: Build Smart, Not Just Fast
The evolution of data engineering continues accelerating, driven by increasing real-time data volumes and stricter latency requirements. Success lies not in building the fastest system possible, but in creating intelligent architectures that balance performance, reliability, and maintainability.
Modern data pipelines must accommodate diverse requirements simultaneously. Streaming data pipelines excel at providing immediate insights through Apache Kafka, while batch processing remains essential for comprehensive analytics using Apache Spark. The most successful implementations combine both approaches strategically, starting with well-designed batch processing systems and gradually introducing streaming components.
Key principles include designing for evolution, prioritizing observability through monitoring frameworks, embracing automation, and considering total cost of ownership across cloud platforms. Organizations should focus on building foundational capabilities that grow with their needs rather than attempting comprehensive real-time systems initially.
At BuildNexTech, we help businesses streamline performance with automated data quality checks, scalable architectures using containerization and microservices, monitoring frameworks for proactive issue detection, and user-focused design that aligns with actual business needs. As a leading web development company, BuildNexTech specializes in custom web development services and builds intelligent backend systems that power modern digital experiences, supporting real-time analytics and future-proof infrastructure.
People Also Ask

How can I reduce latency in a real-time data pipeline without compromising data accuracy?
Use in-memory processing, stream-first frameworks (like Apache Flink or Kafka Streams), and schema validation to balance speed with accuracy.
What are the most overlooked bottlenecks in real-time analytics pipelines?
Serialization overhead, network latency, and slow downstream sinks (like databases or dashboards) are commonly underestimated.
Should I decouple ETL from real-time pipelines or integrate it directly?
Decouple ETL for flexibility and maintainability, but keep lightweight transformations in-stream when ultra-low latency is critical.
How do I choose between Apache Kafka and Amazon Kinesis for my streaming pipeline?
Choose Apache Kafka for open-source flexibility, complex event processing, and multi-cloud deployments. Select Amazon Kinesis for AWS-native integration, managed services, and simpler setup with automatic scaling.
How do I ensure fault tolerance in a real-time pipeline architecture?
Use message replay (Kafka), checkpointing, retries, and distributed systems with high availability to handle failures gracefully.





.webp)
.webp)
.webp)

