


In most banks, compliance slowness has nothing to do with regulation complexity. It comes from four systems that don't talk to each other and a process where data has to be manually copied between screens before anything can move forward.
Hyperautomation in banking connects RPA, machine learning, and NLP into end-to-end workflows that remove manual handoffs from KYC onboarding and AML monitoring. For KYC, this means document verification, risk scoring, and audit logging run automatically. For AML, ML models replace fixed-threshold rules, cutting false-positive rates by 50%+ in documented deployments.
I've watched KYC onboarding drag on for 12 days at institutions where the actual verification call could have been made in 20 minutes. The other 11 days, 23 hours a document sitting in a queue, waiting for someone to open it.
That's what hyperautomation actually solves. Not the compliance decisions. The dead time between them.
What hyperautomation is (and what people usually get wrong about it)
Most people hear "automation" and think bots. A bot fills out a form. A script fires an alert. That's useful, but it's a very small slice of what hyperautomation means.
The real definition is about connecting individual automated steps into a workflow that runs end-to-end without manual handoffs. When document verification finishes, risk scoring starts automatically. When risk scoring produces a result, the case routes to the right queue. Nothing waits for someone to click something.
The tools involved are RPA for structured, rule-obvious steps machine learning for judgment calls like risk scoring NLP for reading unstructured documents and news feeds and an orchestration layer that decides what triggers what. None of those alone is hyperautomation. The connections between them are.
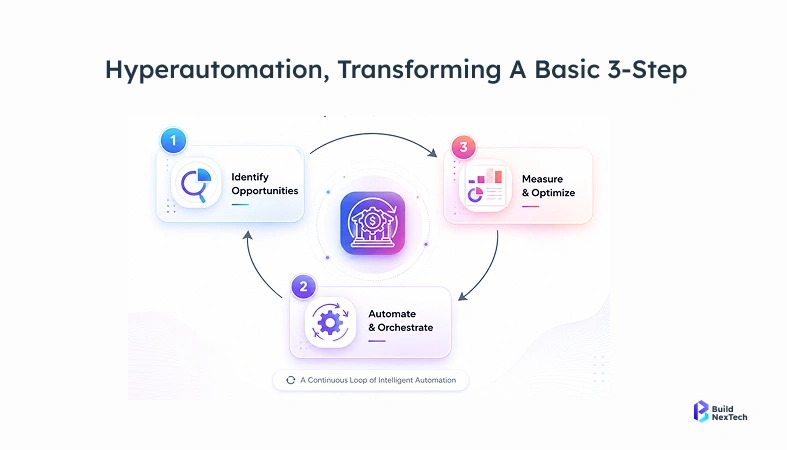
Why banks are moving on this now
For years, hyperautomation lived in pilot project territory. Interesting proof of concept, not quite production-ready, compliance teams unsure whether regulators would accept AI-driven decisions.
That hesitation mostly cleared around 2023–2024. Fenergo's 2023 global enforcement review put total AML fines at $6.6 billion for the year. That's the number that gets a CFO's attention. Transaction volumes kept climbing while compliance headcount stayed flat. And the ML infrastructure got affordable enough that a mid-size bank could actually run models in production without a dedicated data science team to maintain them.
Banks that started serious pilots in 2022 are now running at scale. The ones still evaluating are noticing the gap.
KYC onboarding: where the time actually goes
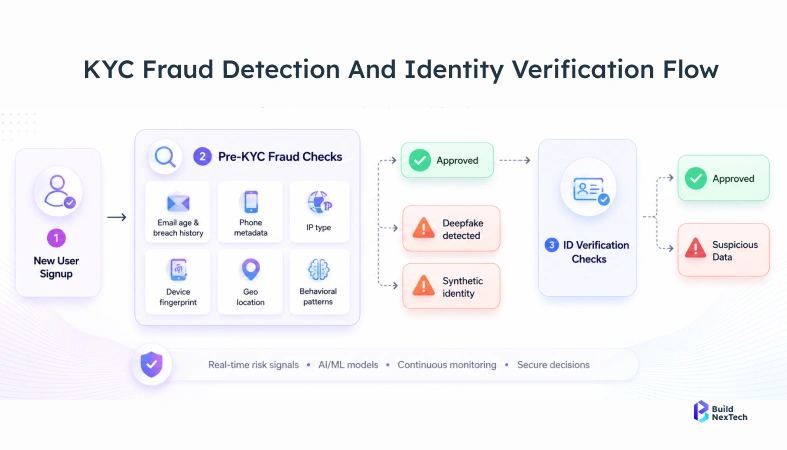
Verification itself isn't slow. Name matching against a sanctions list takes seconds. Document authenticity checks with modern tooling run above 98% accuracy and finish in under a minute.
Everything around verification is slow. The document sits in an inbox for two days. ID check results get typed into the risk scoring system by hand. The risk score lives in one place while the compliance officer who needs to approve it works out of a different system entirely. Nobody designed the process to be slow. It accumulated that way over years of adding tools without integrating them.
Automated KYC eliminates these accumulated handoffs. Document arrives, verification runs, result feeds directly into risk scoring, score produces a decision, audit trail writes itself. A clean case that would have taken eight days can close same-day. Analysts work exceptions the submissions where something doesn't match, or the risk profile is genuinely unclear.
In BNXT.ai's process mapping engagements with mid-size financial institutions, the average KYC backlog delay accounts for over 70% of total onboarding time while the actual verification decision takes under 25 minutes. The rest is queue time.
TABLE: What changes in KYC onboarding
The accuracy improvement in that table isn't purely from better technology. Automated systems apply the same rules to every case. People under volume pressure don't always manage that.
Continuous KYC versus the annual review problem
Most banks still run periodic KYC reviews. Annually for standard customers, more frequently for higher-risk accounts. The schedule is arbitrary, and most compliance officers know it.
A customer's risk profile can shift completely between reviews. New ownership in a corporate account. Transaction patterns that moved toward high-risk corridors six months ago. A news story that would have triggered enhanced due diligence if anyone had caught it.
Continuous KYC watches for those changes as they happen. Ownership change in a corporate filing triggers an automatic review flag. An adverse media hit on a customer name routes to the analyst queue. Sanctions list update runs against the whole book in real time.
It doesn't mean analysts review everything constantly. It means they review accounts that actually changed a much smaller number on any given day than the full scheduled review queue.
AML: the false positive problem is worse than most people outside compliance realise
A mid-size bank can generate over 1,500 AML alerts in a single day. A good analyst clears maybe 40–50 cases in a full shift. Do the math on staffing requirements, then factor in that somewhere between 90 and 95% of those alerts are false positives.
That means an analyst opens a case, reviews it, documents it's not suspicious, closes it, and opens the next one knowing statistically the next one probably isn't suspicious either. It's demoralising, and it burns through analyst capacity that should go toward cases that actually matter.
Rules-based AML systems built this problem. Fixed thresholds don't adapt. They flag the same patterns they were programmed to flag in 2015, including a lot of patterns that turned out not to be suspicious at all, while missing laundering methods that weren't in the rulebook when it was written.
What machine learning actually does differently here
ML models for AML learn what normal looks like per customer type, per account, per transaction corridor and flag deviations from that specific baseline. Not from a universal threshold. From what's normal for that particular account.
A corporate account that regularly moves large amounts internationally looks very different from a retail account doing the same thing. A rules-based system might flag both. An ML model knows the corporate account has always operated that way and flags the retail one instead.
Network analysis adds another layer: clusters of accounts that transact together in structured patterns can look clean individually and suspicious collectively. Sequence models catch transaction chains that suggest layering even when each individual transaction stays below reporting thresholds.ING's deployment of ML-based AML monitoring produced false positive reduction above 50%, based on results they've published in their annual reports. That's not a marginal gain. That's the difference between an analyst team that can keep pace with daily volume and one that permanently can't.
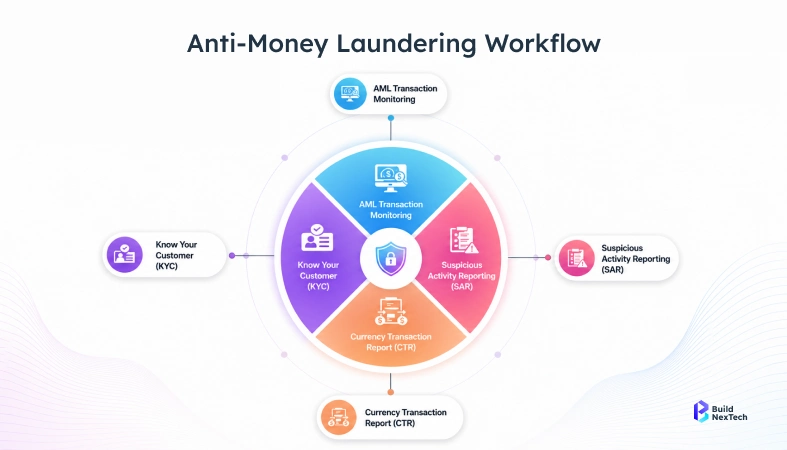
SAR filing: where a lot of analyst hours quietly disappear
Suspicious activity report filing takes longer than it should, and not because the analysis is hard. The analysis is usually straightforward. What eats time is the documentation — pulling transaction data from one system, formatting it to FinCEN or FCA specifications, writing the narrative, cross-referencing it with previous alerts, routing it for review, and submitting it.
Same steps every time. Same data sources, same format, same regulator. Hyperautomation handles the assembly: pulls the data, formats it correctly, pre-populates the narrative from the alert details, and routes it to compliance review. The analyst reads it, adjusts anything that needs adjusting, and approves. They didn't build it. They reviewed it.
For a team filing 40–60 SARs a month, that's a meaningful chunk of hours recovered per week.
The regulatory side: what auditors actually want to see
The table below maps the key regulatory requirements banks face to what automated systems produce as evidence of compliance:
Regulators don't care how fast your process is. They care that it ran consistently and that you can prove it. That's an underappreciated advantage automated systems have over manual ones; a system log is more complete than a folder of screenshots, every time.
The one area regulators push back on is black-box AI decisions. A risk score with no explanation doesn't satisfy an audit. Modern platforms built for financial services output a readable rationale with every decision: what data drove the score, which factors weighted highest, and what threshold it crossed. That explainability layer isn't optional in regulated deployments. Regulators have made clear that AI decisions are acceptable when every decision includes a readable rationale what data drove the score, which factors weighted highest, what threshold was crossed.
Why implementations stall (and it's almost never the technology)
TABLE: Where hyperautomation projects get stuck
Projects that stall almost always stall on data. ML models trained on inconsistent data produce inconsistent scores. Teams discover this six months into the build while debugging model outputs, and the root cause is that the training data had the same address field recorded four different ways across legacy systems.
Fixing that isn't exciting work. Teams that skip it regret it fast.
How to Start: Mapping Before Platform Selection
Don't start with a platform. Start by timing your current process every step, every handoff, every wait. Most compliance teams have never actually measured how long each step takes. They know the total onboarding time but not where the days go.
Once you know where the time goes, the automation priorities become obvious. High volume, low judgement, structured data those go first. Document extraction, sanctions screening, alert triage. It's fast to build, fast to show results, and builds enough internal confidence to tackle the harder stuff.
BNXT.ai works with financial services teams on exactly this starting point: the process audit before the platform decision. The banks that rush to procurement before mapping their current state tend to build automation on top of a broken process and wonder why it doesn't perform.
People Also Ask

What is hyperautomation in KYC and AML, in plain terms?
A document arrives, gets verified, feeds into risk scoring, produces a decision, and logs itself without anyone moving data between systems. The human steps are the exceptions, not the rule.
How does ML actually reduce AML false positives?
ING's published results from their ML-based AML monitoring deployment showed false positive reduction above 50%. That's a practical difference, not a marketing claim — it changes whether an analyst team can actually keep pace with daily alert volume.
Will regulators accept AI-driven compliance decisions?
Yes, regulators, including the FCA and FinCEN accept AI-driven compliance decisions when explainability is documented. Modern platforms designed for regulated industries build that rationale into every model output. Any vendor that doesn't include it by default is worth questioning.
What actually blocks these projects from shipping?
Data quality, almost always. Compliance data spread across old systems with inconsistent formats is the single most common reason timelines slip.
How long does a real implementation take?
A tightly scoped KYC document processing project runs 3 to 6 months from mapping to production. A full AML overhaul with ML scoring runs 9 to 18 months. Both estimates assume the data is reasonably clean going in. Add 3 to 6 months if it isn't and usually it isn't.





.webp)
.webp)
.webp)

