


Choosing between RAG (Retrieval-Augmented Generation) and fine-tuning is one of the first architectural decisions that determines whether your LLM system holds up in production. Deploy the wrong approach, and you risk wasting GPU spend, degraded accuracy, or a system that ages out within months of launch.
Teams that misapply fine-tuning to knowledge retrieval problems lose weeks of compute and return degraded models. The reverse failure is equally costly: retrieval systems deployed against tasks requiring internalized domain behavior, like specialized legal reasoning or clinical NER, consistently underperform fine-tuned baselines. The wrong choice shows up as hallucinations that retrieval could have prevented, or stale model behavior that retraining can't fix fast enough, both with direct cost consequences: wasted GPU spend, re-deployment cycles, or accuracy regressions.
This guide covers how each approach works, where each fails, and how to choose between them, including a decision framework you can apply directly to your stack.
Quick answer: RAG vs fine-tuning, which is better? Neither is universally better. RAG outperforms when knowledge changes frequently, data privacy matters, or you need source-traceable answers. Fine-tuning outperforms when output style, domain reasoning fluency, or specialized behavior is the gap, not missing information.
Fine-Tuning LLM: How It Works and When It Matters
What Is Fine-Tuning in LLMs?
A base language model is trained on broad internet-scale data, giving it general fluency but no exposure to your domain's terminology, workflows, or decision patterns. Fine-tuning is the process of fixing that you run additional training on domain-specific knowledge, specialized terminology, and task-specific patterns until the model starts reasoning the way your domain actually requires.
Under the hood, this means continuing the training process on a curated dataset using a transformer architecture. The model’s weights get updated through neural networks. It absorbs new vocabulary, adjusts tone, and internalizes patterns. Unlike retrieval, that knowledge becomes part of the model itself via transfer learning. Inference is fast because all domain knowledge is baked into parameters. No retrieval step required. The constraint: the model is static until you retrain, making it poorly suited for frequently updated knowledge domains.
Common Fine-Tuning Techniques
Full fine-tuning updates every parameter in the model. Powerful, but the GPU resources cost alone rules it out for most teams outside well-funded AI labs. What most practitioners actually use is parameter-efficient fine-tuning, specifically LoRA or QLoRA, which freezes the majority of the model and only updates small adapter layers. LoRA and QLoRA typically recover 80–90% of full fine-tune performance at 10–30% of GPU compute cost. Hugging Face Transformers makes this accessible enough that even smaller teams can run it without Oracle Cloud Infrastructure-level budgets.
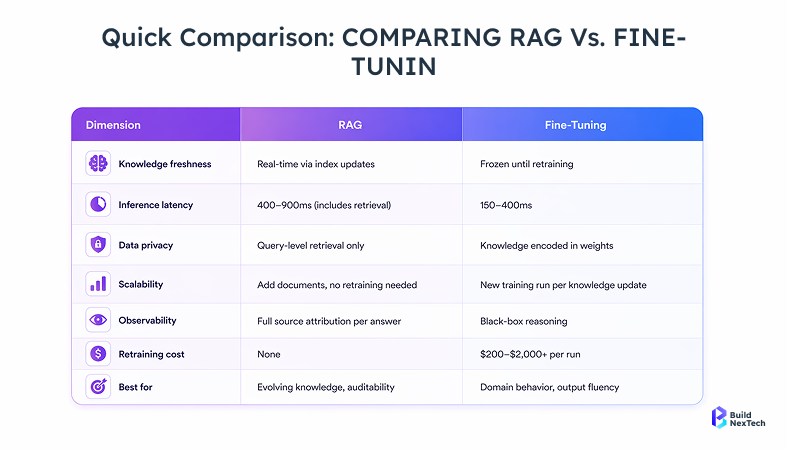
Hyperparameter tuning matters more than most teams budget for. Learning rate and batch size are the two settings that most directly determine whether the model generalizes or overfits. Training duration compounds their effect. Rushed tuning is a common cause of underperformance. Dataset requirements: fine-tuning typically requires 500–10,000 labeled examples at minimum; domain-specific tasks with narrow output formats may need fewer if examples are high quality. Evaluation should include task-specific metrics, F1 score for NER and classification tasks, ROUGE for summarization, and exact match for structured outputs rather than relying on perplexity alone. Inference latency with fine-tuned models is comparable to the base model. There is no retrieval step, so per-query latency runs 150–400ms depending on model size and hardware, versus 400–900ms typical for RAG pipelines with vector search included.
When Fine-Tuning Is the Right Choice
Fine-tuning addresses structural gaps, behavior, reasoning style, output format, not information gaps. Sentiment analysis on highly specialized financial data. Named-Entity Recognition across legal documents with domain-specific terminology. Legal entity recognition in contract terms. Medical diagnosis reasoning over clinical notes. These are behavior problems, not knowledge problems.
The most common misapplication: teams reach for model retraining when the underlying problem is a knowledge gap. If your model doesn't know about your Q3 product update, the fix is retrieval, not retraining. Fine-tuning only operates on data the model was trained on. Retrieval is the correct tool for surfacing information that the model was never given. Applying it to a knowledge problem costs weeks and returns a model no better than before.
Retrieval-Augmented Generation (RAG): A Practical Overview
What Is Retrieval-Augmented Generation (RAG)?
Rather than baking everything into model weights upfront, Retrieval-Augmented Generation gives the model a way to look things up when it needs them. A natural language query comes in, the retrieval system searches a knowledge base document repository, internal data stores, research papers, regulatory filings, whatever your enterprise data looks like, pulls the relevant chunks, and hands them to the generative AI model as context before response generation happens.
The model answers from retrieved information rather than guessing from training memory; hallucinations drop on knowledge-dependent queries, knowledge stays current without retraining, and every answer is traceable to a source document. That traceability matters most in regulated industries where answer provenance is an audit requirement.
How RAG Works in Modern LLM Pipelines
Documents get chunked, converted into LLM embeddings, and stored as embedding vectors in vector databases Pinecone, Weaviate, pgvector, or increasingly in data lakehouses and graph databases, depending on how complex your enterprise systems are. When a query arrives, semantic search finds the most relevant chunks. Those chunks go into the context window, and the large language model generates from there.
Retrieval quality depends most on two decisions: embedding model selection and ranking approach (BM25, dense vector, or hybrid). Chunk size, overlap strategy, and re-ranking layers compound the effect but are secondary tuning targets. Data observability and AI observability tooling aren't optional; once you're in production, you need visibility into what's being retrieved, when it's failing, and why.
Benefits and Limitations of RAG Systems
RAG keeps knowledge current via data pipelines, provides full source auditability per answer, and avoids retraining GPU costs entirely. For teams handling regulated data, medical records, PII, and proprietary documents, retrieving only what's needed per query is a meaningful data privacy advantage over embedding sensitive content into model weights. The constraint is retrieval dependency: output quality is capped by how well your retrieval pipeline performs. A poorly tuned retrieval layer degrades answers regardless of model quality. Vector database overhead at scale also surprises teams that only benchmarked at prototype volume.
RAG vs Fine-Tuning: Key Differences and Trade-offs
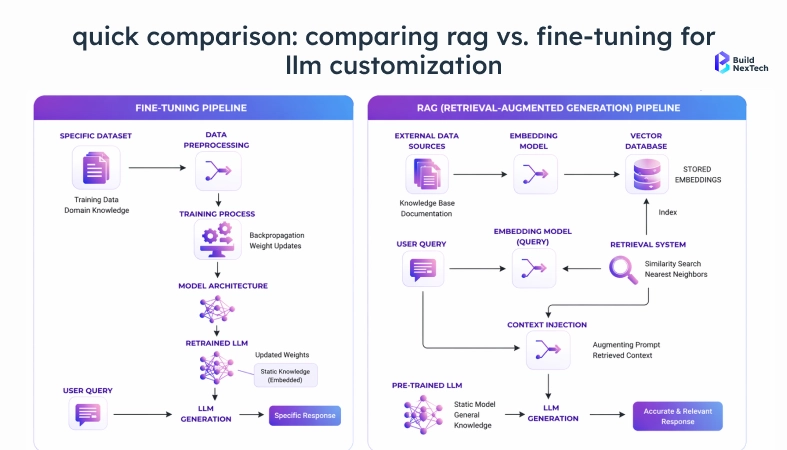
Core Differences
Fine-tuning modifies model parameters: it changes how the model reasons. RAG modifies model input: it changes what the model is given to reason about.
Fine-tuning encodes domain-specific knowledge into model parameters through machine learning. It’s fast at inference time, consistent, and self-contained. But it ages. The moment your proprietary data changes, you’re looking at another training run.
RAG stores knowledge externally in document repositories and knowledge bases always updatable, never requiring model retraining, but dependent on the retrieval system working correctly. One is a training-time operation. The other is inference-time. That difference determines retraining frequency, maintenance cost, and how quickly your system adapts when data changes.
Performance, Accuracy, and Scalability
For narrow, high-stakes tasks like medical diagnosis or legal document review, fine-tuned models with internalized domain knowledge consistently outperform RAG. The model doesn't have to retrieve; domain understanding is already encoded in its parameters through training.
For breadth and adaptability, RAG wins. A customer service chatbot answering questions about products that change every quarter shouldn’t require model retraining every quarter. It should pull from an updated knowledge source. RAG scales horizontally, add documents to your index, update your knowledge base, and change your internal knowledge stores. The AI infrastructure stays the same.
Infrastructure and Operational Costs
Fine-tuning large language models on platforms like Red Hat Enterprise Linux AI or Red Hat OpenShift AI requires real GPU resources. Even with parameter-efficient fine-tuning methods, training a 7B parameter model for a single fine-tuning run typically costs $200–$2,000 on cloud GPU infrastructure (A100/H100, see AWS and GCP pricing), depending on dataset size and epochs. Each subsequent retraining cycle carries the same cost. Oracle Cloud Infrastructure and similar platforms make this more accessible, but the compute cost of model retraining doesn’t disappear.
RAG cost structure is per-query rather than per-training-run: embedding inference adds $0.0001–$0.001 per query depending on model, plus vector database hosting ($50–$500/month at mid-scale). No training compute. At high query volume 100k+ requests/day per-query costs can exceed equivalent fine-tuning amortized over a model's deployment lifetime.
Maintenance and Data Update Costs
This is the cost comparison most teams get wrong. They calculate the initial build cost and stop there.
When your proprietary data evolves, new regulatory standards, updated clinical trial results, revised contract terms, updating a RAG system means re-indexing documents. Fast, cheap, often automated. Updating a fine-tuned model means another training run, another evaluation cycle, another deployment pipeline. Teams that chose fine-tuning without planning a retraining schedule ended up with stale models and silently worsening user experience within six months, a pattern that shows up consistently in enterprise deployments where domain knowledge changes on a quarterly or annual cycle.
Total cost over the model's operational lifetime is the metric that matters, not the initial build cost. For fast-moving domains, that calculation almost always favors RAG.
RAG vs Fine-Tuning in Production
How Teams Use Both in Real Systems
Production-grade implementations treat this as a layered architecture decision, not a binary choice. The architecture separates two concerns: the fine-tuned model governs reasoning, tone, and output structure, while the retrieval system handles current knowledge. Fine-tune for behavior; use RAG for what the model needs to know right now. This layered pattern is what BuildNexTech implements for enterprise teams running knowledge-intensive LLM applications, separating the behavior layer from the knowledge layer at the architecture level.
A legal document analyzer combining both: the fine-tuned model understands contract terms, legal texts, and legal briefs structurally. The RAG layer pulls current regulatory filings, specific legal documents, and recent case references per query. Legal teams get answers that are both domain-fluent and factually grounded in current sources. In a BuildNexTech implementation of this pattern, a legal document review client reduced hallucination rate by 40% while eliminating quarterly retraining cycles.
Real-World Examples
A medical diagnosis assistant for clinical note review: fine-tuned on anonymized medical data to handle clinical language fluently, with RAG pulling drug interaction studies, clinical trial results, medical reports, and medical knowledge base content per query. Medical analysts can ask questions grounded in current clinical trials without the model hallucinating from outdated training data.
A financial advisor chatbot: RAG-only, pulling live market data, financial data, and regulatory standards in real time. No fine-tuning was needed; the base model’s natural language processing capabilities were sufficient. It just needed access to knowledge sources it didn’t have at training time.
A customer support system for a SaaS product: RAG over customer support logs, product documentation, and internal data stores. Response quality improves as the knowledge base updates, with no model retraining required.
RAG vs LLMs: When Retrieval Beats Larger Context Windows
When to Use RAG Instead of Expanding Context
Long-context models handle large inputs well, but stuffing a 100K token context window with documents costs more per inference call, and knowledge retrieval quality often degrades when the model has to surface a specific answer from a massive input.A larger context window increases cost and degrades retrieval precision it does not improve reasoning quality.
RAG is targeted. Semantic search retrieves the 3–5 most relevant chunks for that specific natural language query rather than flooding the context window and hoping. For proprietary enterprise knowledge, document repositories, medical knowledge base queries, or legal document review, targeted retrieval outperforms brute-force context expansion in most real scenarios.
Data privacy pushes in the same direction. With RAG, you’re not sending your entire enterprise data store to an API. You retrieve only what’s needed per query a cleaner posture for systems handling personal identifiable information, medical records, or sensitive proprietary data.
When to Use RAG vs Fine-Tuning
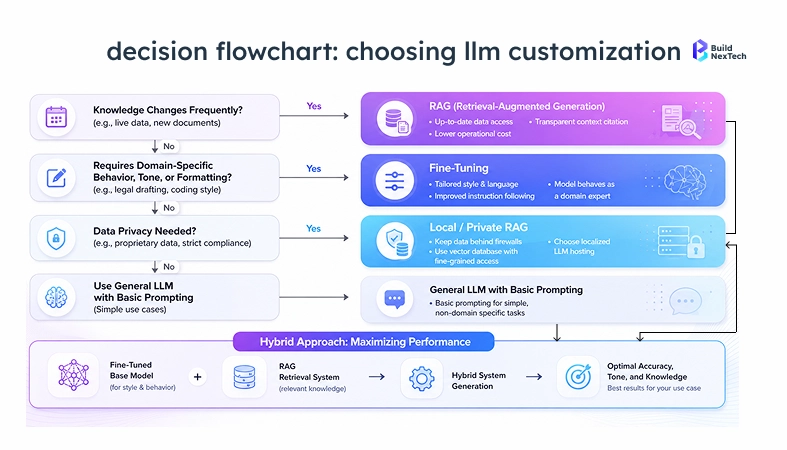
Decision Checklist
Use RAG when your knowledge base changes more frequently than you can afford to retrain, when you need per-query source attribution, or when data privacy prevents embedding proprietary information into model weights.
- Frequent data updates (docs, policies, tickets)
- Need for citations or traceability
- Sensitive/private data constraints
- Large external knowledge sources
- Does knowledge change frequently? → RAG
- Need specialized terminology or domain behavior baked into outputs? → Fine-tuning
- Data privacy or source auditability required? → RAG
- Is the base model just missing current information? → RAG
- Task requires deep domain fluency, medical diagnosis, legal document review, Named-Entity Recognition, and domain-specific translation tools? → Fine-tuning
- Gaps in both knowledge and behavior? → Combine them
Use Cases at a Glance
RAG fits: Customer service chatbots, legal document review tools, question-answering systems over research papers and regulatory filings, content recommendations, educational tools pulling from live knowledge bases, organizational data Q&A over internal data stores.
Fine-tuning fits: Medical diagnosis assistants needing clinical fluency, text mining pipelines for regulatory filings, sentiment analysis on specialized financial data, domain-specific translation tools, any system where the base model’s natural language processing defaults are structurally misaligned with what you need.
Prompt Engineering vs RAG vs Fine-Tuning
Where Prompt Engineering Fits
Before building a RAG pipeline or scheduling training jobs, exhaust what prompt engineering can do. It's the cheapest, fastest intervention, and it's diagnostic. If clear system messages and few-shot examples solve your problem, you didn't need the infrastructure. If they don't, you now know exactly why, which tells you whether to reach for RAG or fine-tuning.
When Prompting Is Enough And When It Isn’t
For standard natural language processing tasks, summarization, basic classification, and straightforward content generation prompt engineering get you most of the way there without data pipelines, vector databases, or GPU resources. It's underused because it feels less sophisticated than building infrastructure, which is exactly why teams skip the cheapest diagnostic step and go straight to a deployment that costs 10x more to unwind.
Prompting breaks down when the large language model fundamentally doesn’t have the knowledge it needs; that’s a knowledge retrieval problem, and RAG solves it. It also breaks down when you’re fighting the model in every prompt to correct its tone, specialized terminology, or output format; that’s a behavior problem, and fine-tuning closes it more cleanly than any prompt workaround ever will.
Conclusion: Choosing the Right Approach for Your LLM Strategy
Retrieval-Augmented Generation and fine-tuning aren’t competing philosophies; they’re tools that solve different problems. The decision sequence follows a clear logic: exhaust prompt engineering first, it costs nothing, and it diagnoses whether you have a knowledge problem or a behavior problem. When knowledge gaps drive failures, build a RAG pipeline. When output behavior, reasoning style, or domain fluency is the bottleneck, fine-tune. For production systems where knowledge freshness and domain fluency both matter, legal document analysis and clinical decision support combine both approaches with proper observability, retrieval evaluation pipelines, and a defined retraining cadence.
In one BuildNexTech implementation of this pattern, a legal document review client reduced hallucination rates by 40% while eliminating quarterly retraining cycles.
People Also Ask

1. Which costs less to run in production RAG or fine-tuning?
RAG has per-query costs ($0.0001–$0.001) plus $50–$500/month for vector storage, with no training overhead. Fine-tuning costs $200–$2,000 per run and repeats with data changes, making RAG cheaper for frequently updated systems.
2. Can RAG fully replace fine-tuning, or do you need both?
RAG cannot replace fine-tuning for behavior issues like format, reasoning style, or terminology, which require parameter-level training. In practice, production systems use both: RAG for knowledge freshness and fine-tuning for domain-specific behavior.
3. Should I use RAG or fine-tuning for a chatbot?
Use RAG for changing data like docs or catalogs, and fine-tuning for persona, reasoning style, or domain behavior. Most chatbots use both—fine-tuning shapes behavior, while RAG keeps knowledge current.
4. Can RAG reduce hallucinations without retraining the model?
Yes. RAG reduces hallucinations by grounding responses in retrieved documents, but its effectiveness depends on retrieval quality. It does not fix reasoning errors or behavior gaps, which require fine-tuning.
5. How does RAG affect latency in production systems?
Expect 200–800ms of added latency per query from the retrieval step alone, depending on your vector database and embedding model configuration. Caching frequent queries reduces this, but latency remains a real user experience trade-off to plan for before production deployment.





.webp)
.webp)
.webp)

