

.webp)
The context, meaning, and similarity recognition in vast amounts of data are among the main characteristics on which artificial intelligence systems rely more and more. Such needs are beyond the capability of traditional databases as they are mainly built for structured records and keyword-based queries. This disparity has resulted in the emergence of the Weaviate vector database which is an AI-native database designed specifically for the support of modern AI workloads.
🔑 Key Topics Covered
- 🚀 Weaviate Vector Database Overview – Understanding Weaviate as an open-source, AI-native vector database
- 🧠 Vector Databases Explained – Core concepts, embeddings, and semantic similarity search
- ⚖️ Weaviate vs Traditional Databases – Comparison with PostgreSQL and MySQL for AI workloads
- 🔍 Semantic Search with Weaviate – How semantic search works with real-world examples
- ☁️ Deployment & Use Cases – Docker setup, Weaviate Cloud, and production AI applications
Selecting the proper AI database is crucial for companies creating AI-based applications like chatbots, recommending systems, and semantic search tools. Weaviate meets this challenge by utilizing vector storage that can scale, sophisticated indexing, and direct links with well-known machine learning and large language model ecosystems. Businesses, for instance, Buildnextech, utilize Weaviate to create large-scale AI systems that connect data engineering with applied artificial intelligence.
Understanding Vector Databases
Semantic similarity, contextual retrieval, and embedding-based search at scale will be ever more possible in modern AI applications due to the support of vector databases. The weaviate vector database gives AI applications a chance to go further than just keyword matching and instead harness the power of high-dimensional embeddings that are coming from unstructured data, including text and images through the means of storage and querying. Such a method is indispensable for the development of applications requiring meaning-aware search and smart data retrieval.
Defining Vector Databases: Characteristics and Functionality
A vector database is an innovative and sophisticated data system that is designed specifically for the storage and access of vector embeddings, which are number-based depictions of unstructured data such as text, images, audio, and video.
Key characteristics of a vector database include:
- Vector storage for high-dimensional vector data generated from unstructured data
- Vector similarity search that retrieves results based on semantic closeness rather than exact matches
- Support for approximate nearest neighbor algorithms to improve speed and scalability
- Built-in indexing mechanisms optimized for large-scale AI workloads
.webp)
By enabling efficient vectorization and semantic representation, vector databases power AI-native applications that require contextual search, ranking, and semantic understanding. A simple vector database example includes searching documents by meaning rather than matching keywords, which significantly improves relevance in AI-powered applications.
Comparative Analysis of Leading Vector Databases
The AI ecosystem presents a variety of vector database solutions, all different from one another in terms of the functions of their strengths. Among the most sought-after are the Milvus vector database, Qdrant vector database, Chroma vector database, and Weaviate. These systems are often compared when teams evaluate free vector databases or open source AI database solutions.
- Milvus vector database is known for high-performance vector similarity search and is widely used in large-scale AI systems.
- Qdrant vector database emphasizes filtering, payload-based queries, and hybrid search use cases.
- Chroma vector database is commonly adopted in lightweight AI-native applications and rapid prototyping.
- Weaviate vector database stands out for its GraphQL-based APIs, built-in hybrid search, and strong integration with AI models and SDKs.
All the mentioned databases offer vector embeddings and similarity search functionalities, However, Weaviate stands out with its developer-friendly experience and production-ready design. Thus, it becomes a perfect match for AI teams who are looking for a mix of scalability, ease of use, and powerful semantic search functionalities.
Architectural Insights into Weaviate
Weaviate is designed as a distributed, cloud-native vector database optimized for AI and semantic search workloads. In a cluster, it separates metadata replication from data replication: cluster metadata (such as collection definitions and shard state) is replicated consistently using the Raft consensus algorithm, ensuring changes are agreed upon even in the event of node failures, while actual data replication uses a leaderless architecture with tunable consistency for high availability and performance. Nodes communicate using a gossip-like protocol for discovery, and any node can act as the coordinator for client read and write operations, directing requests to the correct replica nodes.
The replication factor determines how many copies of each data shard are stored across cluster nodes. A higher replication factor increases availability and read throughput, and Weaviate supports configurable consistency levels per operation, allowing flexibility between speed and strict data correctness. With this architecture, Weaviate balances scalability, fault tolerance, and performance in distributed deployments, making it suitable for real-time, AI-driven applications requiring semantic similarity search at scale.
Key architectural components include:
- A GraphQL query interface for flexible and expressive data retrieval
- Native support for hybrid search, combining vector search with keyword search
- Pluggable embedding models, including integrations with OpenAI, Cohere, and Hugging Face
.webp)
On top of that, Weaviate offers a diverse range of environments for deployment, including local installation, Docker, Kubernetes, and cloud infrastructure provided by the vendors. This aspect grants organizations the freedom to decide if they want to operate Weaviate's database on-site or as a cloud service taking into account their needs regarding security, scalability, and compliance.
Weaviate Deployment Models and Architecture Choices
Weaviate is designed with a flexible, cloud-native architecture that supports multiple deployment models without changing its core functionality. This makes Weaviate suitable for teams at different stages of AI adoption—from early experimentation to large-scale, production-grade systems.
At an architectural level, Weaviate follows a distributed, scalable design optimized for vector storage and semantic search. It separates vector indexing, metadata management, and query execution to ensure high performance and fault tolerance. This architecture allows Weaviate to scale horizontally, handle large volumes of embeddings, and support real-time similarity search with low latency.
Weaviate Cloud vs Self-Hosted Deployments
Weaviate Cloud is best suited for teams that want a fully managed, production-ready environment with minimal operational effort. It offers automatic scaling, high availability, built-in security, and simplified login, allowing organizations to focus on building AI applications rather than managing infrastructure. This model helps reduce time-to-market and is ideal for fast-growing or customer-facing AI workloads.
Self-Hosted Weaviate
- Full control over infrastructure and deployment environment
- Suitable for on-premise setups and private cloud deployments
- Better alignment with strict data governance and compliance requirements
- Customizable networking, security, and resource allocation
Evaluating Weaviate's Role in AI Database Ecosystems
In modern AI database ecosystems, Weaviate complements traditional databases rather than replacing them. Relational systems continue to manage structured records and transactions, while Weaviate is designed for semantic retrieval and AI-driven indexing.
- Role in AI architectures: Foundational component for AI databases and AI-native applications
- Ecosystem integration: Works with OpenAI, LangChain, and Hugging Face for embedding and LLM pipelines
- Workflow enablement: Supports vector embeddings, semantic retrieval, and retrieval-augmented generation
- Deployment strategy: Commonly used alongside relational databases in hybrid architectures
This hybrid approach supports both structured and unstructured workloads and reflects how modern AI systems are built at scale.
Docker and Kubernetes-Based Weaviate Deployments
Docker-based deployment is the fastest way to start using Weaviate, especially for local development, proofs of concept, and early-stage testing. It simplifies setup by handling dependencies and configuration through containerization, allowing developers to spin up a working Weaviate instance in minutes.
Key benefits include:
- Quick and repeatable setup using Docker
- Scalable and resilient production deployments with Kubernetes
- Smooth transition from local testing to large-scale AI systems
Getting Started with Weaviate
Weaviate is designed to make adopting a vector database for AI applications fast, flexible, and production-ready. Unlike traditional databases that require add-ons or major architectural changes to support vector search, Weaviate is vector-native, allowing teams to move smoothly from experimentation to real-world deployment without reworking their core infrastructure.
Based on the official quickstart, Weaviate offers multiple ways to get started depending on your use case—local development, containerized environments, or fully managed cloud setups. This flexibility makes onboarding easier compared to many databases that lock users into a single deployment model or demand heavy configuration early on.
Weaviate also reduces complexity by providing built-in vector search, metadata filtering, and hybrid search in one platform. Where other databases often require separate tools or extensions to achieve similar functionality, Weaviate delivers these capabilities out of the box, helping teams focus more on building AI features and less on infrastructure management.
Overall, getting started with Weaviate is faster and more streamlined than most alternatives, making it well-suited for developers and organizations looking for a scalable, developer-friendly vector database that can grow from prototype to production with minimal friction.
Installation Procedures for Weaviate on Multiple Platforms
Getting started with Weaviate is intentionally simple and consistent across platforms. As outlined in the official quickstart, Weaviate is built to support developers working in local environments as well as teams deploying large-scale, production-ready AI systems. Its installation process is designed to minimize setup friction while keeping the system flexible and scalable.
Weaviate supports multiple deployment options, allowing teams to choose what best fits their workflow:
- Docker-based installation for quick local development and experimentation
- Self-hosted deployments on virtual machines or on-premise infrastructure
- Kubernetes deployments for scalable, cloud-native production workloads
- Managed deployments via Weaviate Cloud for reduced operational overhead
Among these, Docker is the most commonly used approach for getting started, as it eliminates dependency issues and enables a fully working Weaviate instance within minutes.
Docker-Based Quick Start (Recommended)
Below is a minimal Docker setup based on the official Weaviate quickstart guide:
version: '3.4'
services:
weaviate:
image: semitechnologies/weaviate:latest
ports:
- "8080:8080"
environment:
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
DEFAULT_VECTORIZER_MODULE: 'text2vec-openai'
ENABLE_MODULES: 'text2vec-openai'
CLUSTER_HOSTNAME: 'node1'
Run Weaviate using:
docker-compose up -dOnce started, Weaviate is accessible at http://localhost:8080, ready to accept schema definitions, data objects, and vector search queries.
This flexible installation model allows teams to start with local testing and seamlessly scale to production without changing the underlying database setup—making Weaviate an efficient and developer-friendly choice for AI-native applications.
Utilizing Weaviate Cloud: Features and Advantages
Weaviate Cloud provides a comprehensive cloud service management that not only eliminates the operational complexities but also gives the performance quality that is suitable for enterprises. To large-scale AI project teams, a managed cloud service means to them reliability, security, and maintenance that is easy and hassle-free.
Key advantages of Weaviate Cloud include:
- Automated auto-scaling to handle changing workloads
- Built-in multi-tenancy support for SaaS and hybrid SaaS platforms
- Simplified weaviate login and access management
- High availability and optimized scalability
Weaviate Cloud empowers organizations to expedite their time-to-market without compromising the performance of vector search, hybrid search, and semantic retrieval. This strategy is especially beneficial for those AI innovators who are developing AI products that interact directly with customers.
Configuration Best Practices for Weaviate Deployment
Proper configuration is very important for performance, security, and reliability. Weaviate provides a number of configuration options that can help to optimize the deployments according to the various AI workloads.
Recommended best practices include:
- Allocating sufficient memory and CPU resources for indexing and vector storage
- Enabling data sharding and database sharding for large-scale datasets
- Configuring RBAC authorization, API key access, and OpenID Connect
- Monitoring token limits and query performance for LLM-driven applications
The security aspect is as important as the other considerations. Weaviate's support for enterprise-level security, data privacy, and compliance with SOC 2, HIPAA, or similar standards makes it a good candidate for industries under regulation.
Leveraging Weaviate for Semantic Search
Semantic search is a core capability for AI systems that need to understand user intent and contextual meaning rather than rely on exact keyword matches. A weaviate semantic search implementation enables organizations to build search experiences powered by vector embeddings, allowing queries to retrieve conceptually relevant results across large volumes of unstructured data.
Unlike traditional search engines, Weaviate combines vector similarity with structured filters and hybrid search techniques, enabling precise and context-aware retrieval. Whether deployed in production or evaluated against alternatives, Weaviate provides a practical foundation for teams implementing semantic search at scale using modern AI and machine learning workflows.
Principles of Semantic Search: Mechanisms and Techniques
Semantic search goes beyond keyword-based search by focusing on meaning, intent, and context. Instead of matching exact terms, semantic search analyzes vector embeddings to understand semantic representation and semantic understanding. This approach is foundational for modern AI-powered applications.
Core mechanisms include:
- Vectorization of text using embedding models
- Natural language processing to interpret user intent
- Vector similarity and ranking based on contextual relevance
- Combining keyword search with vector search for hybrid results
A practical semantic search example is retrieving relevant documents even when user queries do not contain exact keywords. Understanding how does semantic search work is essential for developers building advanced AI search systems.
H3-Integrating Semantic Search Tools with Weaviate
Weaviate integrates easily with a wide range of semantic search tools and AI frameworks. These integrations enable developers to connect embedding generation, retrieval augmented generation, and LLM pipelines.
Common integrations include:
- Open source AI and GPT-3 for embedding generation and LLM inference
- Hugging Face and HuggingFace models for open-source embeddings
- LangChain and LlamaIndex for building RAG pipelines
- SDKs for Python, JavaScript, and other languages
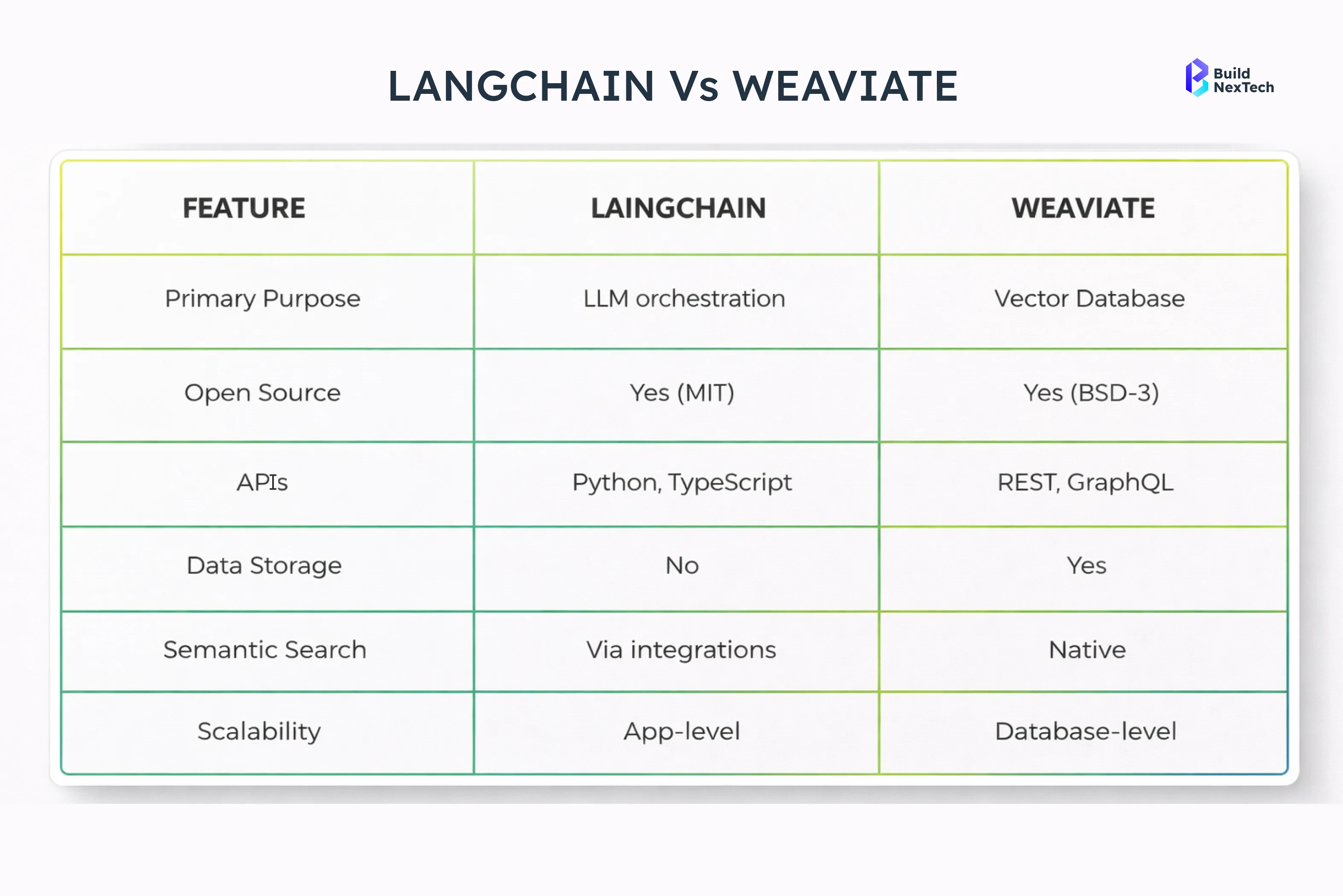
By integrating these tools, Weaviate enables searchable vector databases that support
contextual search, conversational AI, and long-term memory for large language models.
Case Studies: Successful Implementations of Semantic Search
Organizations across industries have adopted Weaviate to build production-ready semantic search systems that improve information retrieval, automation, and personalization.
Enterprise Knowledge Search
Global consulting firms such as PwC and Deloitte operate with millions of internal documents, including policies, research reports, and client deliverables. Traditional keyword-based search often failed when users didn’t know exact terminology. By adopting semantic search powered by vector databases like Weaviate, these organizations enabled meaning-based document retrieval.
Impact: Industry studies show that enterprise semantic search reduces internal search time by 30–50%, translating into thousands of employee hours saved annually and faster, more informed decision-making across consulting and analytics teams.
Customer Support Automation
Customer support platforms such as Zendesk and Intercom apply semantic search concepts to power AI chatbots and intelligent helpdesk systems. Instead of relying on exact keyword matches, vector-based retrieval allows systems to understand user intent and surface relevant answers from historical tickets, FAQs, and documentation.
Impact: Companies implementing semantic search in support workflows typically report 20–40% faster ticket resolution times, 15–30% reduction in agent workload, and noticeable improvements in first-contact resolution and customer satisfaction (CSAT).
Personalized Recommendations
Media and commerce platforms like Spotify and Etsy use semantic similarity and vector search to recommend content and products based on contextual and behavioral relevance, not just keywords. This enables users to discover items aligned with their preferences even when queries are vague or exploratory.
Impact: Publicly shared industry benchmarks indicate that semantic recommendation systems drive 10–30% increases in engagement, longer session durations, and higher conversion rates, directly improving retention and revenue.
These real-world examples highlight how Weaviate enables scalable, accurate, and AI-driven semantic search, helping organizations move beyond traditional search limitations and unlock meaningful insights from their data.
Practical Applications of Weaviate
As AI systems move from experimentation to real-world deployment, the choice of infrastructure directly impacts how effectively applications scale and evolve. Whether teams are evaluating weaviate cloud vs self hosted deployments or starting with a weaviate docker deployment for rapid prototyping, Weaviate provides the flexibility needed to support diverse application requirements.
In comparison-driven evaluations such as the Weaviate vs Milvus vector database, Weaviate often stands out for its ease of integration, hybrid search capabilities, and developer-centric design. These strengths translate into practical advantages across industries, enabling organizations to implement AI-native applications that combine semantic understanding, efficient data modeling, and scalable deployment strategies.
Industry-Specific Use Cases for Weaviate
Weaviate supports a wide range of industry use cases, making it a versatile AI database solution. Its ability to manage unstructured data and semantic queries enables innovation across sectors.
Key applications include:
- AI-powered applications in healthcare, finance, and retail
- Content classification and contextual ranking
- AI-native applications for search, discovery, and personalization
By supporting vector storage and AI-native workflows, Weaviate enables organizations to build scalable AI products aligned with the evolving AI landscape.
Data Modeling Enhancements with AI Diagram and Schema Generators
Weaviate significantly improves data modeling for AI developers by enabling AI-native schema design that aligns naturally with vector embeddings and semantic data. Its integration with AI diagram generators, text-to-diagram tools, AI database generators, and schema generation frameworks simplifies schema creation and accelerates development. Features such as automated schema inference, visual data models, and flexible schema evolution help teams collaborate more effectively, iterate faster, and scale from prototyping to production. By reducing manual schema work, Weaviate allows developers to focus on machine learning models, retrieval logic, and semantic search quality.
Benefits include:
- Automated schema inference for faster onboarding
- Improved collaboration through visual data models
- Faster iteration when designing AI-native databases
Before adopting Weaviate, AI teams often struggled with manual and time-consuming schema design, frequent refactoring as models evolved, poor visibility into complex data relationships, and slow onboarding for new developers. Data schemas were tightly coupled with application logic, making experimentation risky and iteration slow. These challenges increased operational overhead and reduced development velocity. Weaviate addresses these issues by offering a developer-friendly, AI-first data modeling approach that removes friction, improves adaptability, and supports rapid innovation in AI systems.
Future Trends: Evolving Applications of Weaviate in AI
As artificial intelligence continues to advance, vector databases will play an increasingly central role. Future trends include deeper integration with foundation models, LLM models, and state-of-the-art ML models.
Emerging developments include:
- GPU-accelerated vector search using NVIDIA, NVIDIA B200, and GPU-native vector search algorithm technologies
- Advanced retrieval augmented generation pipelines using RAG (retrieval-augmented generation)
- Growth of agentic workflows, Agentic AI, and AI factories
These trends position Weaviate as a core component of next-generation AI systems.
Conclusion: The Role of Weaviate in AI Databases and How bnxt.ai Enables Scalable AI Systems
Weaviate has emerged as a foundational open-source AI database for applications that rely on vector embeddings, semantic search, and context-aware data retrieval. By addressing limitations of traditional databases in handling unstructured data, Weaviate enables AI-native architectures that are better suited for modern workloads involving large language models, semantic search, and intelligent agents.
Platforms like bnxt.ai build on these capabilities by helping organizations design, deploy, and scale end-to-end AI systems. By leveraging Weaviate as part of a broader AI architecture, bnxt.ai enables teams to move from experimentation to production with greater efficiency, ensuring that AI applications remain scalable, adaptable, and aligned with real-world business needs.
🔑 Key Takeaways from This Guide include:
- Vector databases like Weaviate are essential for AI systems that require semantic understanding rather than keyword-based retrieval
- Weaviate complements traditional databases by handling unstructured data, embeddings, and similarity-based search
- Flexible deployment options—self-hosted, Docker, Kubernetes, and cloud—make Weaviate suitable for diverse AI environments
- Semantic search and RAG pipelines built on Weaviate improve relevance, contextual accuracy, and AI system responsiveness
- bnxt.ai enables scalable AI architectures by integrating vector databases, LLMs, and modern AI workflows into production-ready systems
Together, Weaviate and bnxt.ai provide a practical foundation for organizations aiming to build intelligent, future-ready AI applications that can scale with evolving data and model complexity.
People Also Ask

What is the difference between a vector database and a traditional database?
Vector databases store and retrieve high-dimensional vector data for semantic similarity, while traditional databases manage structured records using tables and SQL.
What are some examples of open-source databases?
Common open source database examples include PostgreSQL, MySQL, MongoDB, Elasticsearch, Milvus, Qdrant, Chroma, and Weaviate
What is semantic search and how is it different from traditional search?
Semantic search focuses on meaning and context rather than exact keyword matching, enabling more accurate and relevant results.
Can I use Weaviate for free, and what are its limitations?
Yes, Weaviate is open source and free to use. Managed cloud services may have usage-based limitations.
How does Weaviate handle data security and user authentication?
Weaviate supports RBAC, API keys, OpenID Connect, and compliance standards to ensure secure data access.





.webp)
.webp)
.webp)

