


Amazon Prime Day is one of the world’s largest online shopping events, where millions of users simultaneously browse, add items to shopping carts, and compete for time-limited deals. Traffic spikes to extreme levels within minutes, testing even the most robust cloud computing platforms. For Amazon, Prime Day is not just a sales event—it is a live stress test for cloud infrastructure, demonstrating the importance of availability, scalability, and fault-tolerant system design.
To handle extreme load, Amazon relies on a combination of autoscaling, caching layers, load balancing, and fault isolation, orchestrated across its Amazon Web Services (AWS) ecosystem. Technologies such as the AWS load balancer, including the Elastic Load Balancer (ELB) and Application Load Balancer (ALB), a ct as core components of the Amazon load balancer strategy. This load balancer AWS setup efficiently distributes traffic across healthy services, ensuring fast, reliable, and uninterrupted shopping experiences even during peak traffic.
This Blog Will Cover:
- Prime Day traffic surges and their unique characteristics
- Autoscaling strategies with EC2, AWS Lambda, and Kubernetes
- CDN and in-memory caching for high performance
- Load balancing across regions to prevent bottlenecks
- Fault isolation and cell-based architecture for resilience
- Observability and monitoring using CloudWatch, AWS X-Ray, and distributed logging
What Really Happens When Prime Day Goes Live?
When Prime Day goes live, traffic surges globally within seconds. Millions of users trigger requests for product descriptions, warehouse inventory, shopping carts, and deals simultaneously.
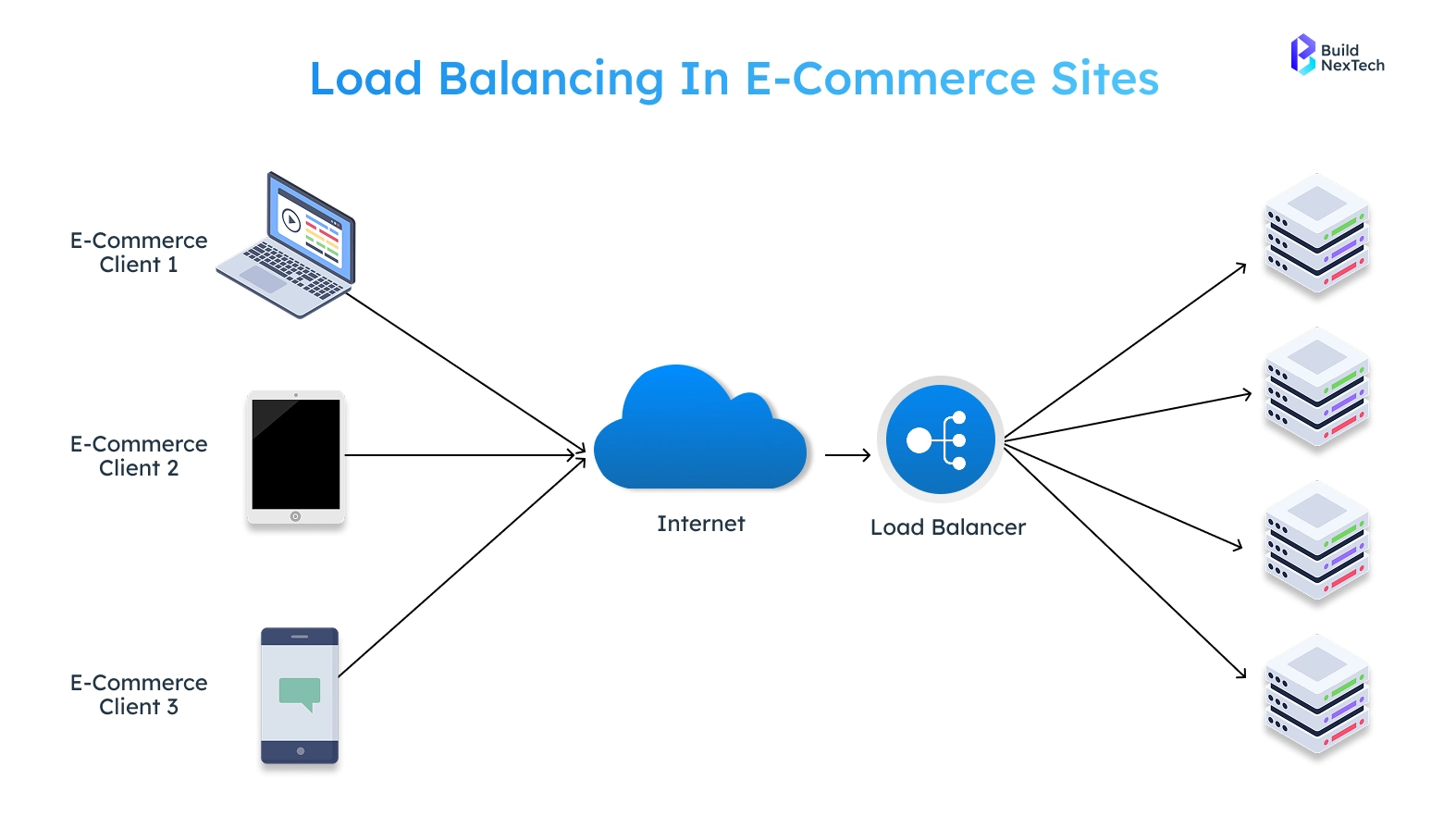
Behind the scenes, Amazon’s cloud infrastructure handles billions of requests per hour. Load balancers distribute traffic efficiently to prevent any single server from becoming a bottleneck. Every click is routed through Elastic Load Balancing (ELB), Application Load Balancers (ALB), and global load balancers for optimal performance.
Why Prime Day Traffic Is Unlike Normal E-commerce Load
Prime Day traffic is far more intense and unpredictable than typical e-commerce activity. Instead of gradual increases, traffic spikes suddenly, often surging 5–10× normal levels within minutes. Hot deals create concentrated demand on specific pages, and global, synchronised user activity combined with frequent page refreshes and cart updates makes the load highly erratic.
Key Characteristics of Prime Day Traffic:
- Bursty Request Patterns: Extreme peaks in seconds.
- Heavy Read and Write Activity: High load on Amazon DynamoDB, Amazon Aurora, and inventory systems.
- Region-Specific Surges: Traffic peaks vary geographically, requiring multi-region failover.
- Intense Backend Pressure: Core services face massive load, challenging databases, distributed cache, and compute resources.
Dynamic cloud infrastructure management and advanced load balancing networking ensure real-time scaling instead of relying on static capacity.
How Amazon Scales in Minutes, Not Days
Amazon scales in minutes, not days, by leveraging auto scaling across its cloud infrastructure services. As a leading cloud infrastructure provider, AWS offers flexible solutions that enable EC2 Auto Scaling, Kubernetes auto scaling, and serverless services to dynamically scale compute resources up or down based on real-time demand.. This cloud infrastructure as a service model ensures each microservice can handle sudden traffic spikes independently, maintaining performance and reliability without manual intervention.
Predicting the Surge Before It Hits
Amazon predicts traffic surges using historical data, real-time metrics, and machine learning models to forecast demand patterns. This allows systems to pre-scale resources before peak traffic arrives, ensuring seamless performance.
- Forecast-Driven Scaling: Historical Prime Day data, generative AI, and load tests predict traffic surges.
- Pre-Scaling Across Regions: Critical services scale ahead of time to prevent cold starts and reduce latency.
- Proactive Resource Management: Ensures availability and scalability before traffic peaks.
Scaling Each Service Without Breaking the System
Amazon scales each microservice independently, so a surge in one area—like search or checkout—doesn’t overload others. This prevents bottlenecks and ensures overall system stability during Prime Day traffic spikes.
- Microservices Architecture: Search, recommendations, checkout, and payments scale independently.
- Service-Specific Autoscaling Policies: Fine-tuned for each service, including Amazon EC2 Auto Scaling and AWS Lambda.
- Efficient Cloud Infrastructure Management: Monitors resources via, AWS Systems Manager, and distributed logging to prevent over-provisioning.
Why Caching Is Amazon’s First Line of Defense
Caching is Amazon’s first line of defense because it absorbs massive traffic before it reaches core systems, preventing backend overload. By storing frequently accessed data closer to users—through CDN caching, in-memory caches like Redis, and query-level caching—Amazon reduces latency and server strain. During peak traffic, these caching layers ensure fast page loads, reliable product information, and uninterrupted shopping experiences, acting as a protective buffer against sudden demand surges.
Serving Millions Without Touching the Backend
Amazon serves millions of users without overloading backend servers by using Content Delivery Network (CDN) caching. Static assets like images, scripts, and product descriptions are delivered from edge locations close to users, reducing latency and backend requests.
- CDN Caching: CloudFront delivers static/semi-dynamic content from edge locations.
- Reduced Latency and Load: Offloads traffic from backend servers, ensuring fast video playback, product descriptions, and deal content.
Keeping Hot Data One Step Away
Amazon keeps frequently accessed dynamic data—such as prices, inventory, and user sessions—one step away using in-memory caches like Redis. This allows the system to serve requests in microseconds, reducing load on databases during traffic spikes.
- In-Memory Caching: Stores dynamic data like prices, sessions, and inventory in Redis or Amazon ElastiCache.
- Distributed Cache: Enables millisecond response times and reduces repeated database queries.
Reducing Database Pressure at Peak Scale
Amazon reduces database pressure during peak traffic by using read replicas, query-level caching, and database replication across regions. These strategies ensure that databases like DynamoDB and Aurora remain responsive, even under massive Prime Day load.
- Optimized Databases: DynamoDB Global Tables, Amazon Aurora, and Amazon Redshift handle high throughput.
- Query-Level Caching & Read Replicas: Maintain consistent performance under extreme load.
What Happens When Something Still Fails?
Even with strong systems in place, failures can still happen due to unexpected bugs, traffic spikes, or external outages. When something fails, automated monitoring quickly detects the issue and triggers alerts. Traffic is rerouted, affected services are isolated, and fallback mechanisms keep the core experience running. Teams then analyze the failure to fix the root cause and strengthen the system for the future.
Isolating Failures Before Users Notice
Through strong AWS partnership practices, failures are contained by isolating affected services so they don’t cascade across the system. This approach ensures most users continue to experience a stable, uninterrupted service without noticing any disruption, even during high-traffic events.
- Microservices Isolation: Failures in recommendations or Amazon SQS don’t affect checkout or search.
- Blast Radius Limitation: Contained failures protect availability and user experience.
Stopping Failures from Spreading
Systems use fault isolation and circuit breakers to prevent a failing component from impacting others. By limiting the blast radius, issues are contained quickly and overall performance remains stable.
- Circuit Breakers – Automatically stop requests to a failing service to prevent overload and allow it time to recover.
- Retries – Reattempt failed requests in a controlled manner to handle temporary issues without overwhelming the system.
- Timeouts – Limit how long a service waits for a response, ensuring resources aren’t blocked by slow or unresponsive components.
Why Amazon Uses Cell-Based Architecture
Amazon uses a cell-based approach within its cloud infrastructure architecture to divide its massive system into small, independent units called cells. Each cell can handle traffic on its own, supported by Kubernetes auto scaling and deep cloud infrastructure automation, so if one cell fails, the impact is limited and does not affect the entire platform. This design also enables flexibility across hybrid cloud infrastructure and multi cloud infrastructure environments, improving fault isolation, scalability, and overall system resilience especially during extreme events like Prime Day.
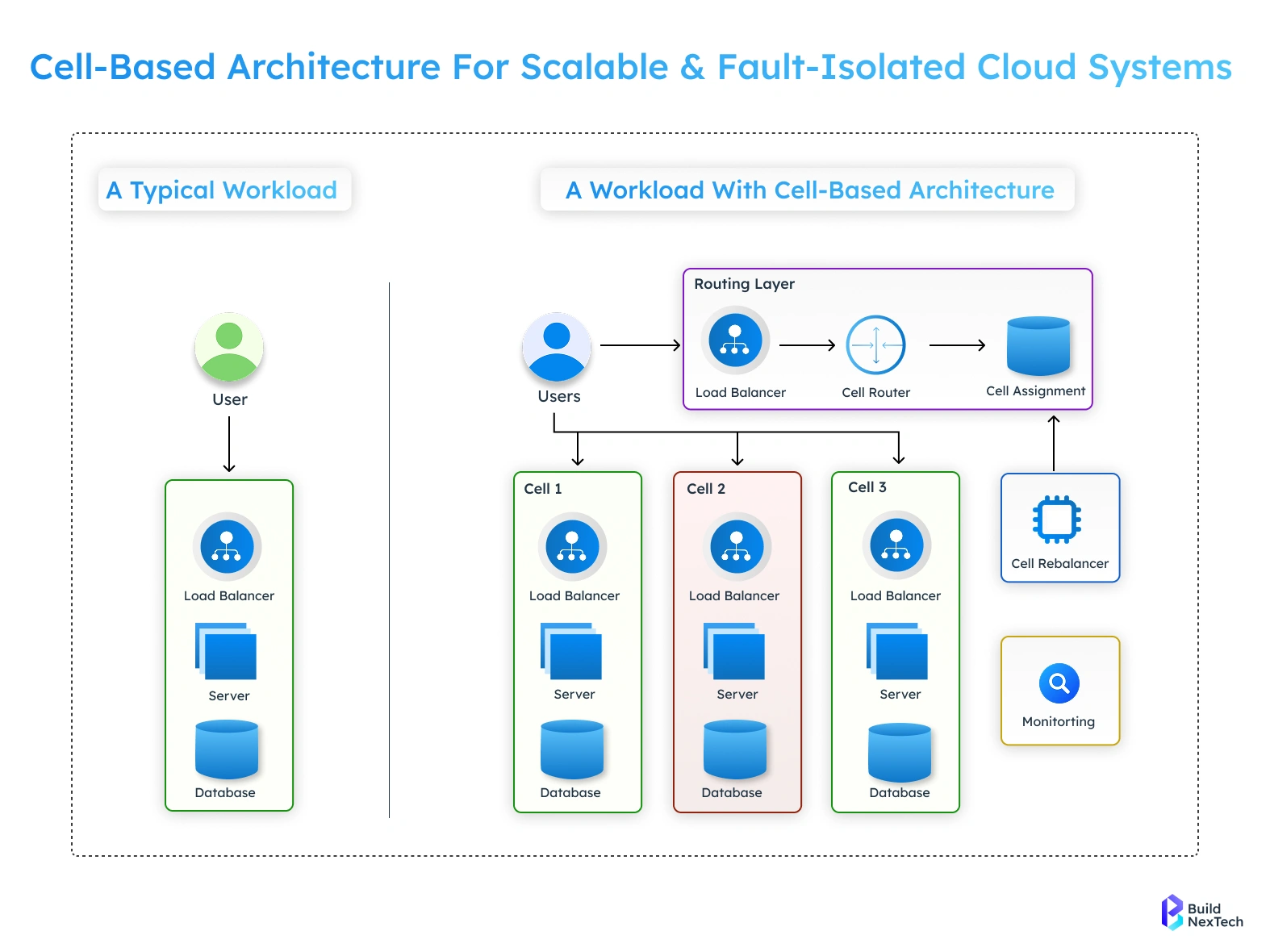
- Independent Cells: Each cell contains critical services and data.
- Traffic Routing Across Healthy Cells: Global load balancers reroute traffic seamlessly if a cell fails.
How Traffic Is Routed Without Creating Bottlenecks
The load balancing system intelligently distributes all incoming requests to multiple services, regions, and cells using intelligent load balancers. All requests are sent to the healthiest and least loaded set of instances based on current activity, which prevents hotspots due to overall balanced incoming traffic volume. Therefore, users do not experience any delays or interruptions from sudden spikes in incoming requests and do not create any congestion.
Routing Requests to the Fastest, Healthiest Services
Requests are routed dynamically to the service with the lowest latency and best health metrics to provide users with the fastest possible responses and automatically route around the slowest or least healthy services.
- Health-aware routing is calculated based on the latency, health, and region of the service.
- The Application Load Balancer uses the request headers and request paths to route to the quickest and most responsive endpoint.
What Gets Throttled First During Extreme Load
Core user actions are prioritized and protected first, by throttling any non-critical features and background processes during times of extreme load. Therefore, all APIs, recommendations and analytics workloads are provided rate limits so that essential services such as search, cart, and checkout can be maintained in a stable manner.
- When extreme loads occur, recommendations as well as personalization features will be throttled.
- Normal checkout, shopping cart and authentication services remain operational.
How Engineers See Problems Before Customers Do
To quickly detect when anomalies occur, engineers rely on real-time monitoring, logs, and metrics. They use automated alerting systems that highlight abnormal levels of latency, error rates, or traffic patterns before these conditions reach their end-users. Dashboards and tracing tools give teams the ability to identify the source of the problem immediately, and take preventative action.
Watching Metrics, Logs & Traces in Real Time
- Engineers monitor CloudWatch, AWS X-Ray, and distributed logging.
- Metrics track system health, latency, error rates, and throughput.
- Proactive monitoring enables rapid response to failures before customer impact.
What Other High-Traffic Platforms Can Learn from Prime Day
Other high-traffic platforms can learn that scale alone is not enough—resilience must be engineered into the system. Prime Day highlights the importance of autoscaling combined with data caching strategies such as Redis caching and CDN caching to absorb sudden traffic spikes. Proactive monitoring, along with throttling non-critical features, helps protect core user experiences and maintain stability during peak load.
- Build for Failure, Not Perfection: Ensure critical workflows continue during failures.
- Combine Autoscaling and Caching: Protect backend databases, Amazon S3, and compute resources.
- Isolate Services: Contain failures and prevent system-wide impact.
- Invest in Observability Early: Real-time dashboards and alerts detect issues fast.
- Design for Peak, Not Average Load: Enables scalability, availability, and seamless customer experience.
Applicable for streaming platforms, fintech, global SaaS, and other cloud computing platforms.
Final Takeaway: Resilience Is Built Before the Sale Starts
Amazon prime day is not an accident, it has been planned. Adhering to the AWS Well-Architected Framework, Amazon constructs resilient e-commerce systems using microservices and scaling, as well as possessing high security. Offering features such as Amazon S3, Amazon EventBridge, AWS Step Functions, Amazon SNS and message queues, event-driven workflows can be configured to provide auto-recovery and the platform can sustain giant spikes in traffic without affecting the system.
Amazon achieves resiliency with the help of autoscaling, load balancing, database replication, and real-time monitoring using AWS Distro for OpenTelemetry. Quick changes can be quickly and safely facilitated with the help of safe release methods like Blue/Green releases, Canary releases, and feature toggles and kill switches. Good DevOps culture, war rooms, and a set of support plans will allow responding swiftly to such events as Prime Day and Big Billion Day.
With the help of AI, large language models, and Amazon SageMaker AI, such as Rufus AI Shopping Guides on the Amazon Mobile App, customer experience is improved, and insights obtained by Numerator are utilized to plan the demand and traffic. Through the implementation of autoscaling, layered caching, real-time monitoring, and fault isolation organizations can ensure steady performance throughout peak traffic.
People Also Ask

Why does Amazon plan Prime Day events far in advance?
Amazon plans Prime Day using the AWS Well-Architected Framework to ensure scalability, security, and reliability. Advance planning allows systems to handle massive traffic spikes without affecting performance or customer experience.
How does Amazon handle extreme traffic during Prime Day?
Amazon uses autoscaling, load balancing, microservices architecture, and message queues to distribute traffic efficiently. Real-time monitoring and auto-recovery mechanisms help maintain system health during peak loads.
What AWS services support Prime Day resilience?
Key services include Amazon S3, Amazon EventBridge, AWS Step Functions, Amazon SNS, and AWS Distro for OpenTelemetry. These services enable event-driven workflows, monitoring metrics, and fault isolation at scale.
How does Amazon reduce deployment risks during Prime Day?
Amazon uses Blue/Green deployment, Canary releases, feature toggles, and kill switches to safely roll out changes. These approaches help detect issues early and prevent widespread failures.
What can organizations learn from Amazon’s Prime Day strategy?
Organizations can build resilience by adopting autoscaling, layered caching, real-time monitoring, and fault isolation. Planning for failure from the start ensures stable operations during high-traffic events.





.webp)
.webp)
.webp)

