


In 2025, GitHub processed one billion commits for the entire year. By April 2026, it was hitting 275 million commits every single week. That is not growth. That is a category shift - and Azure's AI infrastructure was not architected to absorb it. The result: Microsoft, a company that has committed $190B to Azure as its flagship AI cloud, had to contract AWS to keep its own developer platform online.
If your team builds on Claude Code, AI coding agents, or any developer platform touching git repository operations, this is not about Microsoft's embarrassment. It is about what happens when agentic AI workloads hit infrastructure designed for human-scale traffic. Across 150+ client engagements in engineering modernisation and cloud migration, our teams at BuildNexTech have watched this exact pattern emerge - the agent traffic problem arrives before anyone has built the architecture to handle it.
What Actually Broke: The Numbers Behind GitHub's AI Workload Explosion
GitHub COO Kyle Daigle did not hedge in the company's public postmortem. The commit volume surge was driven almost entirely by AI agents - Claude Code, Claude's Code variant workflows, GitHub Copilot, Cursor, Devin - not new human developers. Each AI-generated pull request triggered a cascade of operations hitting GitHub APIs at machine speed:
- Database writes to the git repository and mergeability checks.
- Merge queue operations and webhook fan-outs to downstream services.
- Runner allocation for GitHub Actions and artifact storage writes.
Agents bypassing the UI via direct CLI and REST calls meant every operation a single human developer performed now fired simultaneously across thousands of concurrent sessions. This is AI-native development at scale.
The numbers confirm the scale of the shift. Weekly compute minutes hit 2.1 billion in a single week in early 2026, up from 500 million in 2023. AI agent pull requests surged from four million per month in September 2025 to 17 million by March 2026 - a 325% increase in six months. The merge queue alone, which serialises competing pull requests to protect branch integrity, became a bottleneck no human-traffic capacity model had anticipated. Developer productivity AI tools and AI pair programming platforms are no longer auxiliary products. They are the platform's primary load driver.
Why GitHub's 10x Capacity Plan Became a 30x Emergency
GitHub CTO Vlad Fedorov confirmed a 10x capacity expansion plan launched in October 2025. By February 2026, that target had been revised to 30x - because the AI workload curve outpaced every model the infrastructure team had built.
The February 9 incident exposed three compounding infrastructure challenges at once:
- Cascading coupling: An overloaded authentication database cluster took down GitHub Actions, Copilot, and the web UI simultaneously - because the monolith's near-two-million-line Ruby on Rails codebase had no service isolation boundaries to contain blast radius.
- Git storage write amplification: Agents running squash merge operations at machine speed generated storage pressure that the tier had never experienced at that frequency.
- No load-shedding: The system had no mechanism to circuit-break misbehaving clients. Engineers across the industry were refreshing the GitHub status page, watching services flip red one by one.
Code completion AI tools running as agents had created a load profile that the architecture was never designed to serve.
The Multi-Cloud Response: Why Microsoft Called AWS and What That Signals
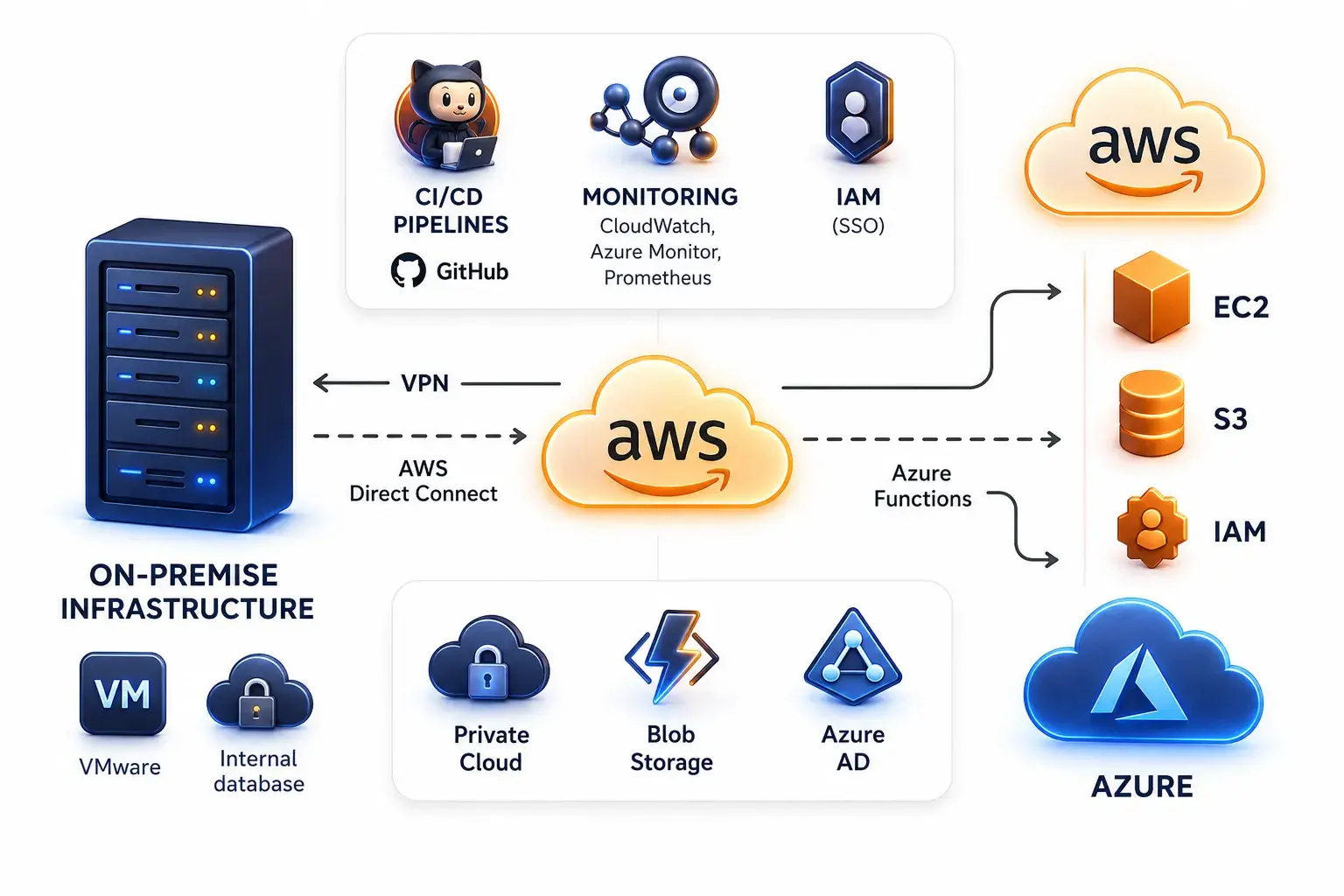
The Microsoft-AWS move is the first hyperscaler-scale demonstration that even the most resourced organisations cannot always expand IaaS capacity fast enough to absorb agentic traffic growth in real time. AWS EC2 Elastic Compute Cloud was available immediately. Azure's capacity expansion for GitHub's specific migration workload was not.
As of June 2026, GitHub's multi-cloud architecture stands at: 40% of monolith traffic on Azure Central US (up from 8% in February), 30% of git traffic migrated, 99% of repository replication completed, and AWS absorbing overflow AI agent traffic. A live 30x redesign is running while the platform remains in production.
Microsoft's framing is a multi-cloud strategy as a resilience measure. It also exposes a risk every engineering team on a single IaaS provider must confront: single-provider dependency creates blast radius risk that agentic workload growth will expose faster than any capacity plan anticipates. According to McKinsey's 2025 technology infrastructure report, organisations that lack elastic multi-cloud capacity are significantly more vulnerable when AI-driven workload spikes exceed single-provider provisioning limits - and most enterprise teams are building on architectures designed before that shift was visible. The Azure vs AWS cost debate is secondary. Whether your multi-cloud architecture exists at all when you need it is the real question.
The Vendor Lock-in Risk Hiding Inside Enterprise AI Infrastructure Decisions
AWS Bedrock's AgentCore, Azure AI Foundry, and Google Cloud's Agent Engine each embed agent runtime, memory management, and session state inside the hyperscaler's own PaaS layer. Each increases cloud vendor lock-in in ways that are invisible until a migration becomes necessary.
The 2026 Zapier enterprise survey found 81% of enterprise leaders were concerned about AI vendor dependency, with 47% reporting that a key business function would stop if their primary AI provider went down. Beyond availability, there is a security dimension: agents operating at machine speed across automation pipelines and security services create a significantly wider surface area for online attacks than any human-operated workflow. Cloud portability is no longer theoretical. The teams treating hybrid cloud as a long-term goal rather than a current design constraint are the most exposed.
The correct architectural response:
- Model abstraction layers over commodity APIs to avoid runtime lock-in.
- S3-compatible storage interfaces rather than proprietary object stores.
- Open source orchestration standards (MCP, LangChain) that decouple agent runtime logic from any single provider.
An enterprise cloud strategy built on cloud portability from day one is cheaper than a migration executed under production pressure.
What the GitHub Crisis Reveals About Agentic AI Workload Architecture
GitHub's crisis is an architecture mismatch, not a capacity story - and the distinction matters for every engineering team building on AI infrastructure today.
The branch-PR-CI-webhook model was designed for human commit rhythms. AI agents fork git repositories, push branches, open a pull request, and trigger automation pipelines at machine speed across thousands of repos simultaneously. Traditional cloud AI optimises for stateless LLM serving: send a request, get a response, done. Agentic workloads are stateful and long-running - a single agent task may trigger multiple inference infrastructure calls, CI runner allocations, and webhook fan-outs before it resolves. That is an AI platform scalability problem, not an LLM inference problem.
Deloitte's 2026 Tech Trends report is direct: the AI infrastructure reckoning has arrived. Cloud TCO implications are immediate: GPU cloud capacity priced for batch inference is now consumed continuously by agent runtime loops, with no off-peak window to manage cloud egress cost or cloud CapEx predictably.
Designing CI/CD and Developer Platform Infrastructure for Agent-Scale Traffic
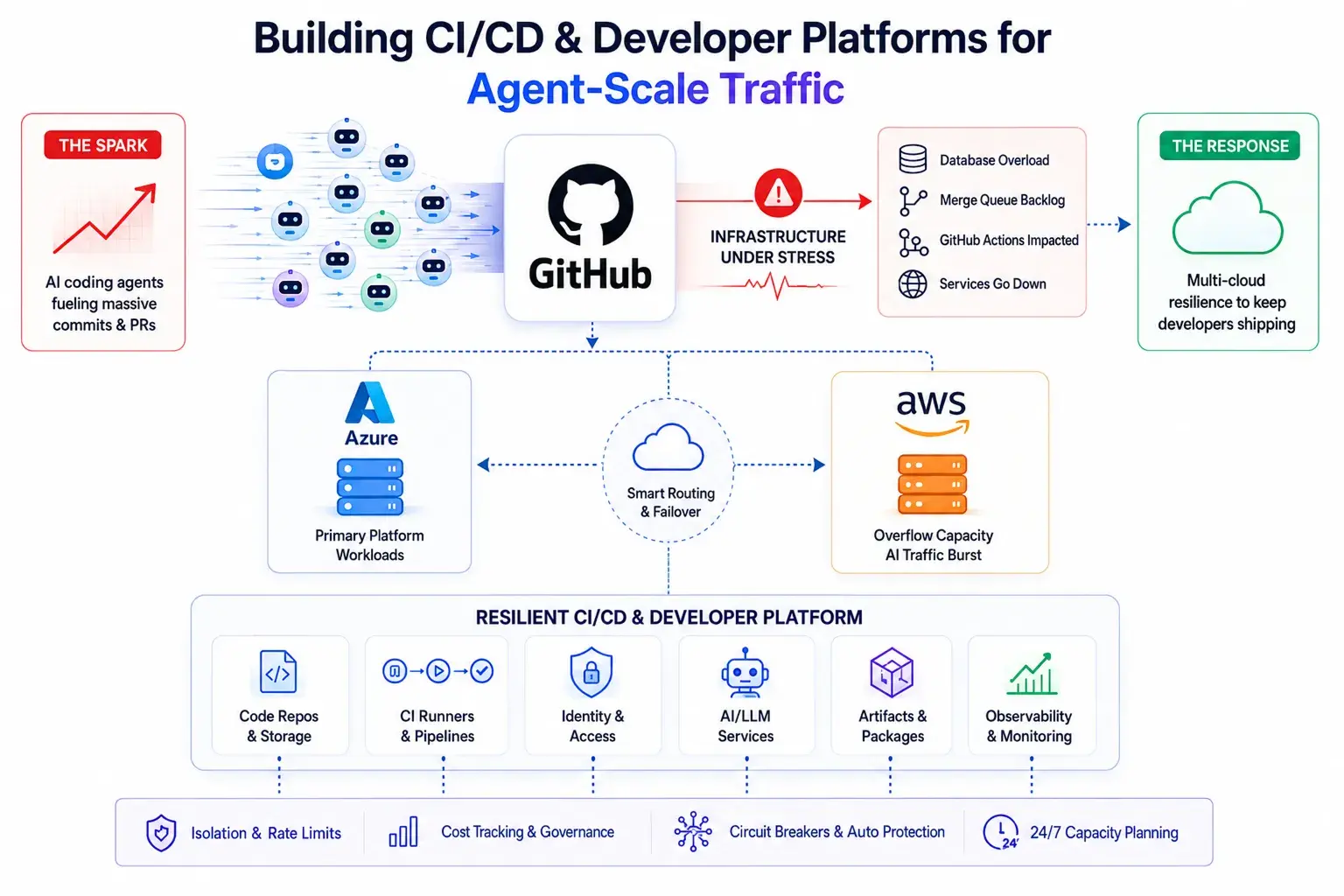
Three architectural principles apply immediately. None requires a full platform rewrite.
1. Classify agent traffic at the gateway: Separate agent sessions from human sessions at the API gateway or inference infrastructure layer. AI compute consumed by agents must be rate-limited, cost-tracked, and circuit-broken independently - not pooled with human developer allocations.
2. Isolate critical services: Code storage, CI runners, and identity/auth must run on isolated compute pools. Large Language Models powering AI developer tools require low-latency LLM serving that competes with the same cloud capacity used for platform compute. Automated code review triggered by agent pull requests consumes inference capacity that was never factored into the original platform budget.
3. Plan for 24/7 flat load: AI compute provisioning should assume sustained peak-hour load around the clock. AI-driven software development workflows have no off-peak. Infrastructure that does not account for this will produce a 30x surprise.
How BuildNexTech Helps Engineering Teams Build AI Infrastructure That Doesn't Break Under Agentic Load
A logistics firm came to us in late 2025 with a problem their cloud vendor had not flagged. Their AI-driven software development pipeline saturated their cloud computing services layer every morning before human dispatchers arrived - because nobody had applied independent rate limits and circuit breakers to agent sessions before the system scaled. After BuildNexTech redesigned the agent traffic layer, peak queue wait times dropped from 34 minutes to under 90 seconds - a 40% reduction in six weeks. The risks that caused that failure appear in nearly every engineering team building on AI infrastructure today:
- Tight architectural coupling with no service isolation.
- Human-pattern capacity planning that misses 24/7 agent load.
- No agent traffic classification or session-level cost tracking.
- Single-provider IaaS dependency with no overflow capacity.
BuildNexTech's AI-native agent builder - via our AI services practice - gives platform teams the load visibility and observability across token usage, latency, session state, and cost per agent run that GitHub's monolith lacked. Teams have reduced AI deployment time by 10x, shipping production-ready multi-agent systems in days, not quarters.
What a BuildNexTech AI Infrastructure Implementation Looks Like
The implementation runs in four phases:
- Day 1-3 (Discovery): Map existing agentic AI projects, LLM provider dependencies, and CI/CD integration points. Identify where agent traffic is undifferentiated from human platform traffic.
- Day 4-7 (Integration): Connect BuildNexTech's orchestration layer to existing model APIs and instrument the inference infrastructure with observability hooks. No rearchitecture required.
- Week 2 (Deployment): First production agent workflows running with real-time cost tracking, latency dashboards, and model routing active.
- Week 3+ (Iteration): Define agent traffic policies - rate limits, circuit breakers, cost budgets per session type - and establish capacity planning baselines agent-native observability makes possible.
Who This Is For
The teams that benefit most from a BuildNexTech engagement share these characteristics:
- Running agentic AI projects in production - or preparing to - with at least one Claude Code agent, AI coding assistant, or CI automation agent integrated into the developer platform
- CI automation pipelines are already showing queue delays from agent commits, with no clear answer on whether it is a scaling or architecture problem.
- Evaluating proprietary agent runtimes against cloud portability, or planning a multi-agent deployment with no agent-level observability yet in place
If any of those describe your team, that is the conversation worth having first.

The Architecture Lesson Every Engineering Team Needs to Hear Now
GitHub's crisis is the clearest live case study yet of what AI infrastructure looks like when agentic workloads outgrow the architecture designed to serve them. Bringing in AWS services was not a failure of Microsoft's cloud ambitions. It was a failure of capacity planning models that assumed human traffic patterns in a world that had already moved past them.
The engineering teams that build agent traffic classification, service isolation, cloud-portable orchestration, and agent-native observability now will not be executing a 30x redesign under production load in two years. AI infrastructure decisions made today are not reversible cheaply under load. What does not vary is the cost of discovering that gap at scale rather than in a design review.
People Also Ask

Why did Microsoft use AWS services for GitHub instead of Azure?
Azure's capacity expansion for GitHub's specific migration workload could not be provisioned fast enough to absorb the agentic traffic surge. AWS EC2 elastic compute was immediately available as overflow IaaS, while Microsoft's long-term target remains full Azure migration by 2027.
What is agentic AI infrastructure, and how is it different from standard cloud AI?
Agentic AI infrastructure handles stateful, long-running workloads that loop, tool-call, and trigger cascading platform operations - unlike stateless LLM serving. Session state management, sustained flat load curves, and circuit-breaking at the agent layer are requirements that standard cloud AI infrastructure was not designed to meet.
What does the GitHub AI outage mean for enterprise teams using GitHub Copilot or AI coding tools?
GitHub's nine May 2026 outages breached enterprise SLA commitments below the 99.9% threshold, with agent session wait times hitting 54 minutes during peak incidents. Engineering teams should treat GitHub as critical infrastructure requiring resilience planning, not as an invisible utility.
How do you design AI infrastructure for a multi-cloud strategy without creating vendor lock-in?
Use model abstraction layers over commodity LLM APIs, S3-compatible storage interfaces instead of proprietary blob storage, and open source orchestration standards like MCP and LangChain. These three patterns keep agent runtime logic separable from any single cloud provider's managed infrastructure stack.
What is the difference between IaaS, PaaS, and SaaS in the context of AI infrastructure?
IaaS (AWS EC2, Azure VMs) provides raw compute; PaaS (Azure AI Foundry, AWS Bedrock) provides managed AI platform services; SaaS (GitHub itself) sits on top. A SaaS platform's reliability is directly bound by the IaaS layer beneath it and the agent traffic patterns running through it.





.webp)
.webp)
.webp)

