

.webp)
A fintech startup came to us eight months into their microservice architecture build with a problem nobody had flagged. They had decomposed their monolithic application into fourteen independent services, containerised everything with Docker, and shipped to Kubernetes. Six months later, a single degraded Payment Service was collapsing their entire checkout flow. The Order Service hung. The Inventory Service backed up. The on-call engineer spent two hours tracing the failure across a stack with no distributed tracing and no Circuit Breaker in sight.
‘They had adopted microservice architecture. They had not adopted microservice patterns.’
According to a 2023 O'Reilly Software Architecture survey, engineering teams applying formal design patterns report 43% greater deployment agility than teams that improvise their service topology. In 2026, with cloud platforms accelerating adoption and DevOps practices maturing across every sector, the gap between pattern-aware and pattern-ignorant teams is wider than ever. Across 150+ client engagements at BuildNexTech, the teams shipping production-ready microservices cleanly are the ones who treat microservice patterns as a sequencing decision, not a checklist.
Why Microservices Architecture Demands Explicit Design Patterns
Microservice architecture style offers real advantages: independent services that deploy autonomously, polyglot persistence, and team-level ownership at scale across complex software applications. What it does not offer is automatic resilience or consistency. Those come from deliberate pattern choices.
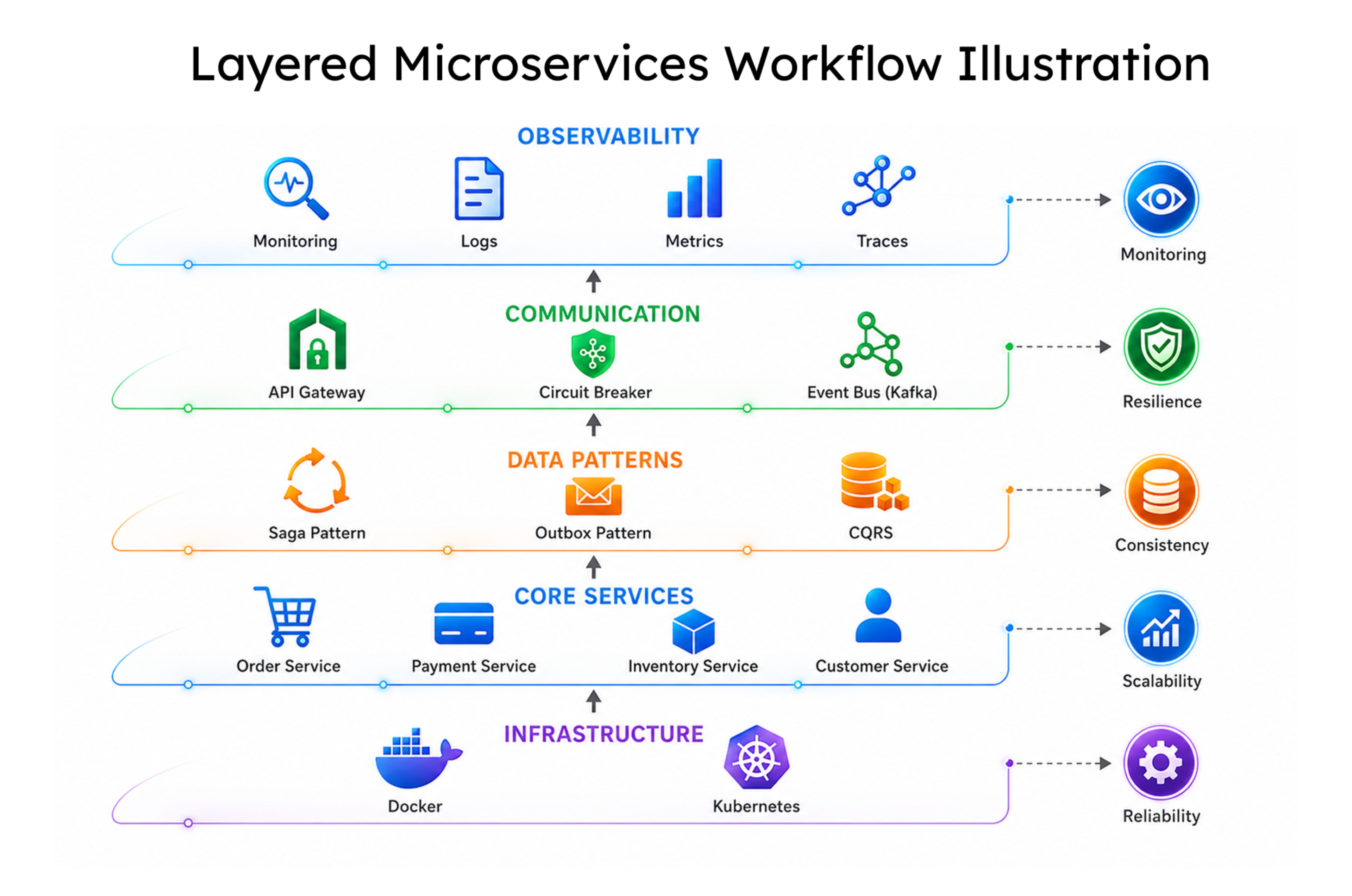
The failure mode most teams hit is the distributed monolith. Services are technically separate but operationally coupled, through shared databases, synchronous call chains with no fault isolation, or event pipelines added as an afterthought. Monolithic systems gave teams ACID transactions and a single deployment unit. Microservice architecture trades those guarantees for scalability and team autonomy. The microservice patterns in this guide exist to fill what that trade removes: fault isolation, data consistency, and end-to-end system visibility.
Monolithic vs Microservices: When the Trade-Off Is Worth It
A monolithic application gives you transactional consistency and a single deployment unit. Microservice architecture gives you independent scaling and team autonomy, at the cost of distributed system complexity.
The modular monolith is a valid intermediate step for teams below twenty to fifty engineers or early-stage software applications without divergent system scalability requirements. Three signals indicate it is time to decompose: independent service scaling requirements that conflict within the monolith, team topology conflicts around shared codebases, and deployment bottlenecks in which one team's release blocks another's.
Decomposition Patterns: How to Break a Monolith Correctly
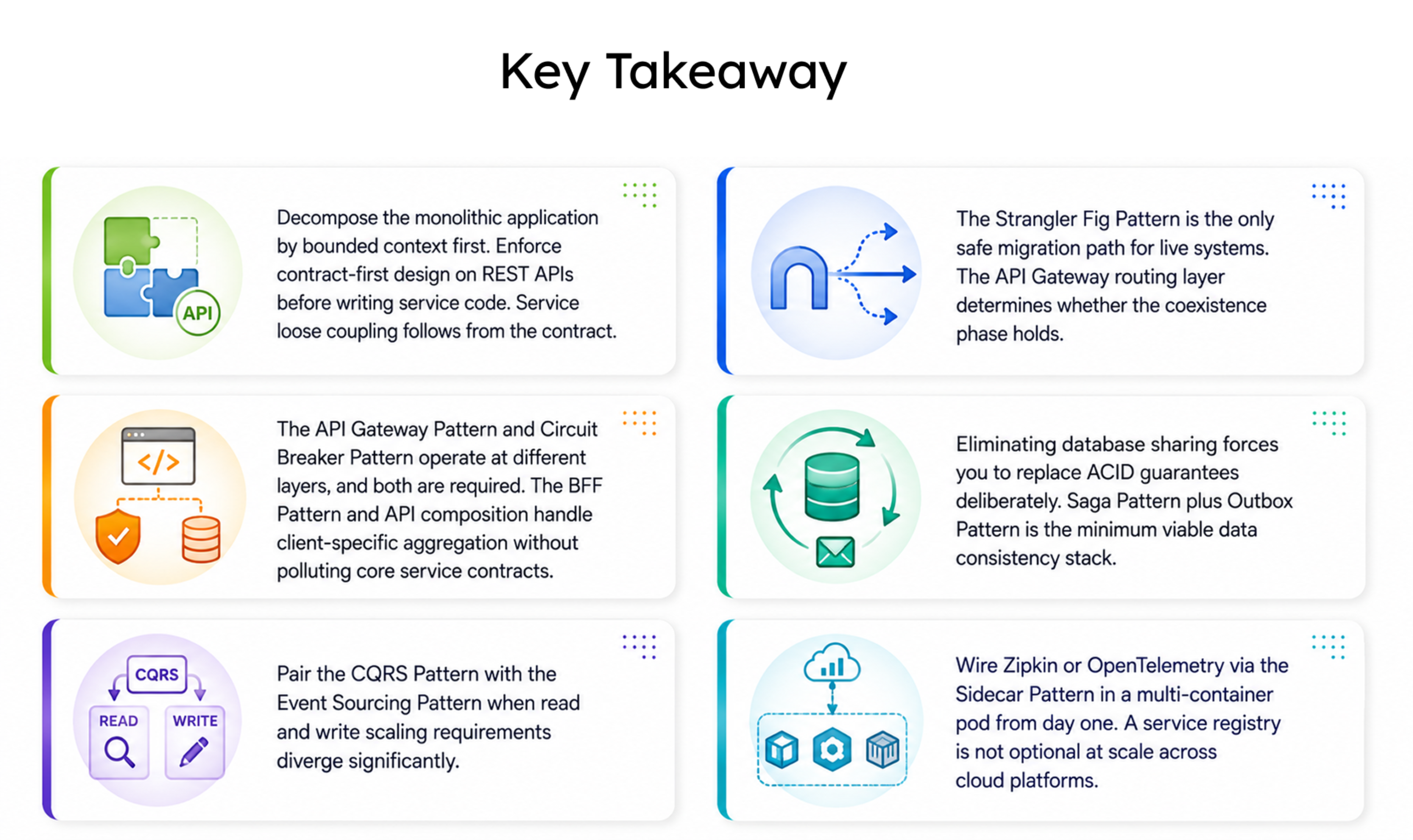
Start with the clearest bounded context: the part of the system with the fewest shared dependencies and the most independent scaling requirements among business entities.
Two strategies cover most scenarios. Decomposed by Business Capability for greenfield software applications with distinct organisational functions. Decomposed by DDD Bounded Context for complex brownfield migrations where shared business entities like Order or Customer resist clean separation. Contract-first design on REST APIs before writing service code is one of the most under-applied best practices in early decomposition work. Service loose coupling follows from the contract, not the other way around.
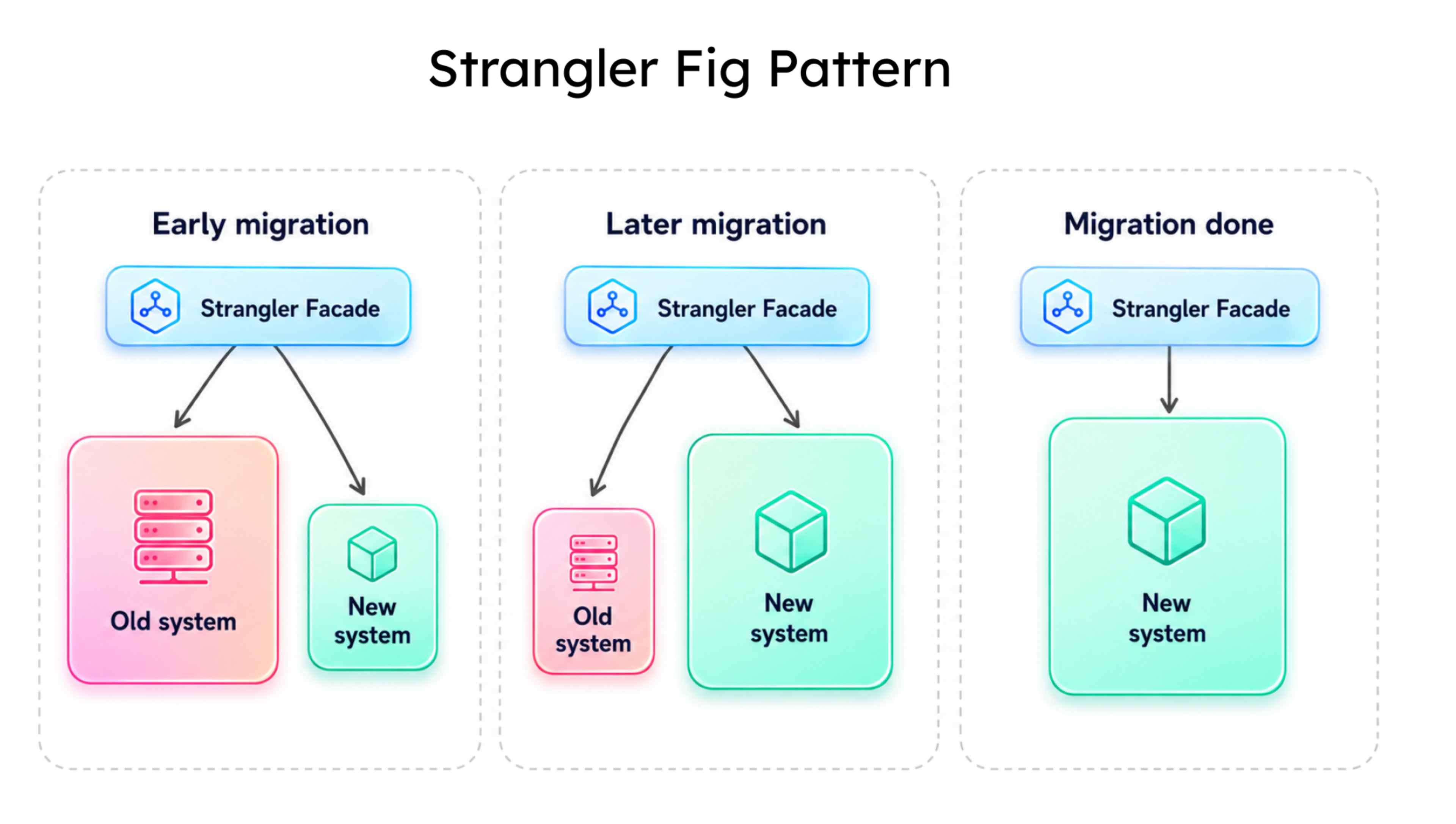
Applying the Strangler Fig Pattern to a Live System
The Strangler Fig Pattern is the only production-safe migration path for live monolithic systems. Three phases: Transform (build the new service behind the API Gateway while the monolith continues serving traffic), Coexist (route traffic to both legacy and new service in parallel, with the API Gateway acting as the routing switch), and Eliminate (decommission the legacy code path once the new service is validated).
Docker containerises the new service during Transform. Kubernetes runs both versions side by side during Coexist. The API Gateway routing configuration is the part most articles underspecify and the part that determines whether the coexistence phase holds under production load.
Communication Patterns: Synchronous vs Asynchronous Inter-Service Calls
Synchronous REST APIs create a direct dependency between caller and callee availability. At scale, one slow downstream service cascades latency across the entire call chain.
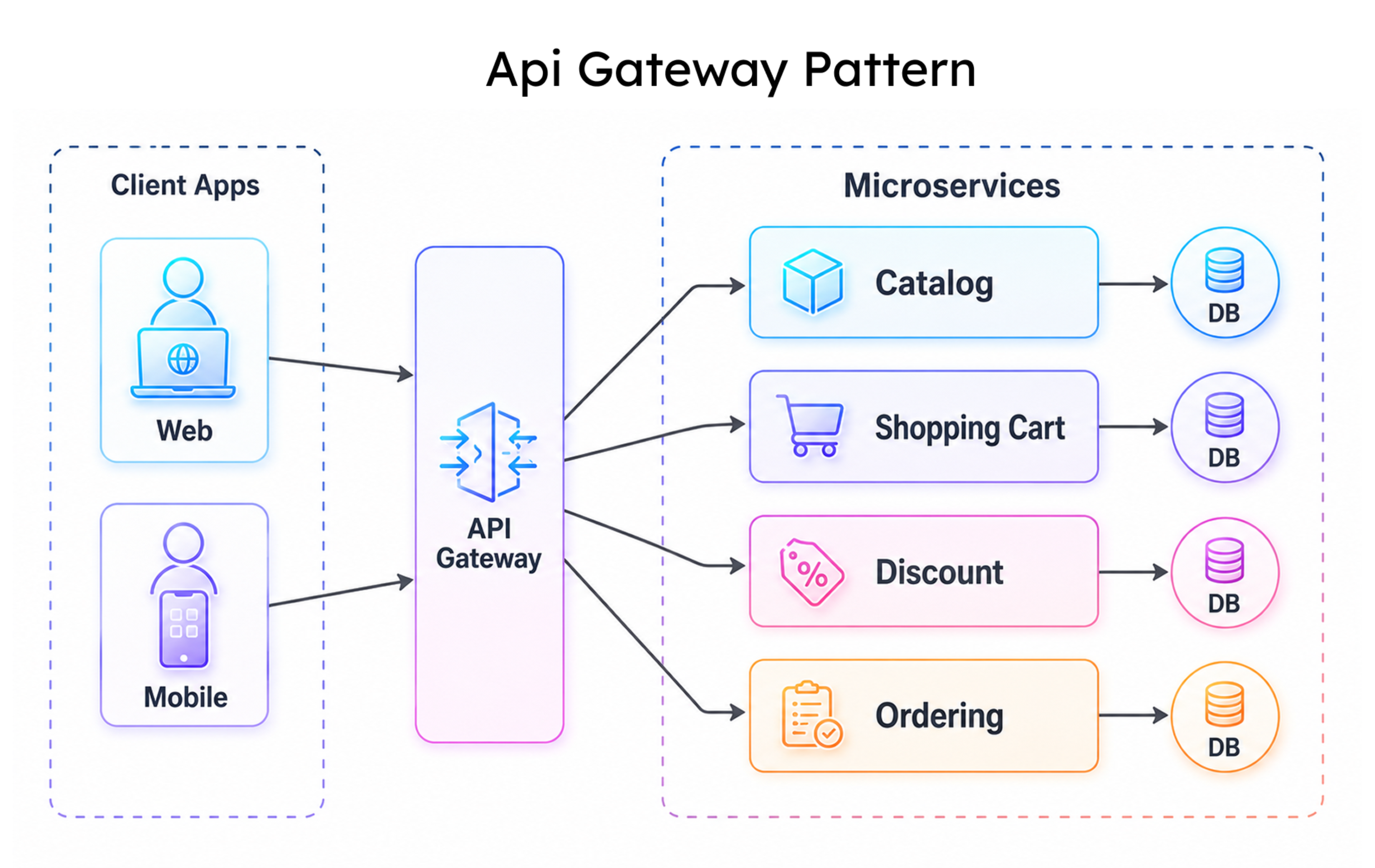
API Gateway Pattern: Routing, Auth, and Rate Limiting in One Layer
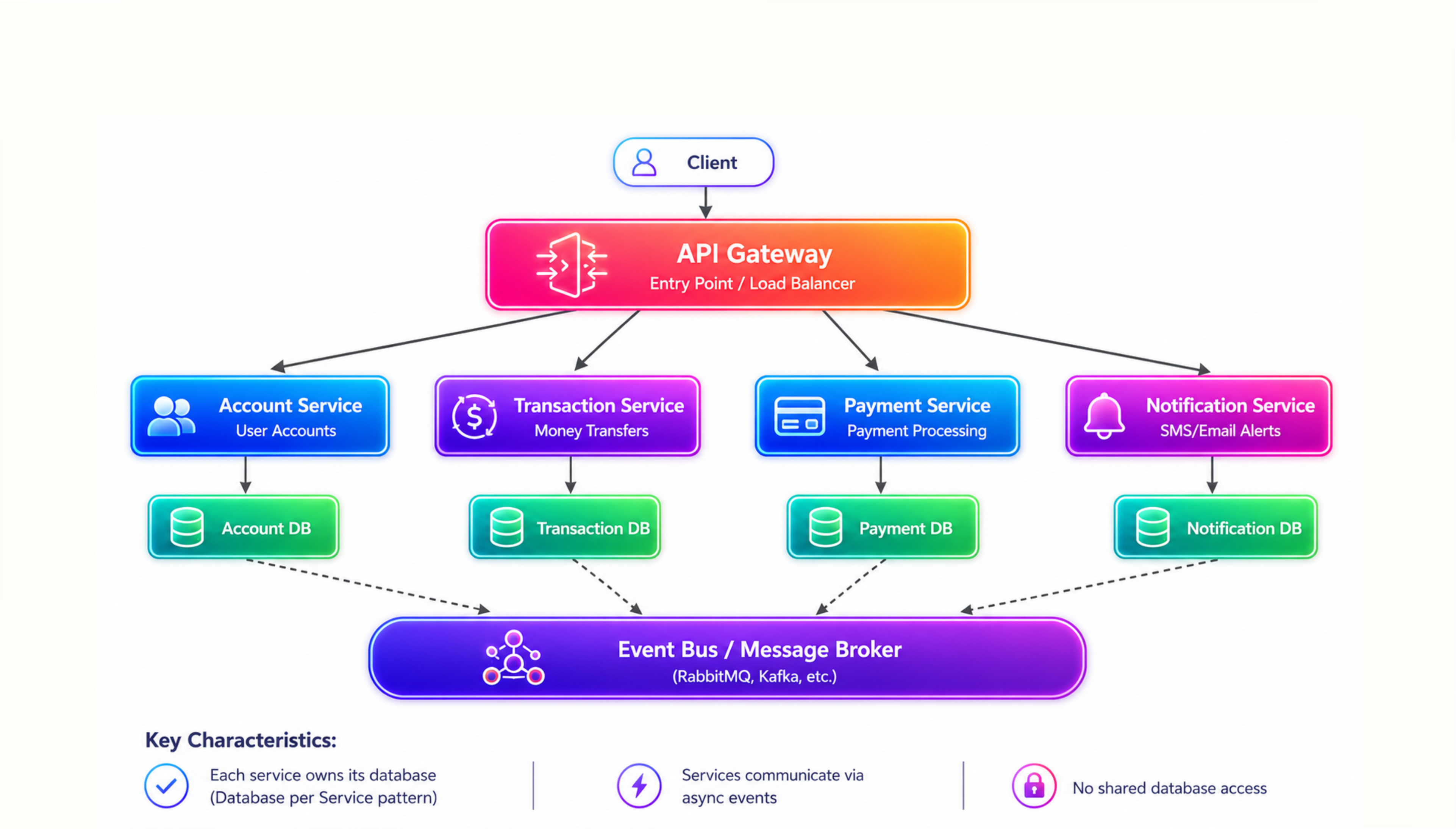
The API Gateway Pattern gives cloud application deployments a single, governable entry point. It centralises routing, handles JWT authentication and OAuth 2.0 authorisation for user management flows, manages rate limiting, and terminates SSL, removing cross-cutting concerns from individual service codebases.
The BFF Pattern extends this: when mobile and desktop clients need structurally different response shapes, a BFF layer behind the gateway handles client-specific aggregation via API composition without polluting core service contracts.
Circuit Breaker Pattern: Preventing Cascading Failure Across Services
The Circuit Breaker Pattern wraps each service-to-service call with a failure threshold policy. When the downstream service fails beyond that threshold, the breaker trips to Open and returns a cached or queued fallback response instead of blocking the caller. Three states: Closed (normal operation), Open (calls fail fast), Half-Open (probe request tests recovery).
For the Order Service calling the Payment Service: if the Payment Service degrades, the Circuit Breaker queues the order rather than collapsing checkout. The API Gateway and Circuit Breaker operate at different layers, and both are required. For asynchronous communication, Event-Driven pattern architecture via Kafka or RabbitMQ decouples services at the message broker level, enabling system scalability without rewriting inter-service dependencies as the service count grows.
Our Take: The API Gateway and Circuit Breaker are not alternatives. An API Gateway with no Circuit Breaker on downstream calls is a well-organised single point of failure. Wire both from day one.
Data Patterns: Managing Consistency Across Service Boundaries
Eliminating database sharing is the foundation. Each service owns its data store and exposes data only through its API contract. No shared schemas. Traditional ACID transactions spanning service boundaries are gone, and two-phase commit is operationally untenable at scale.
Saga Pattern: Distributed Transactions Without 2PC
The Saga Pattern coordinates a multi-step distributed transaction through a sequence of local transactions, each publishing an event that triggers the next step. On failure, compensating transactions roll back each completed step in reverse. Two execution models: Choreography (services react to events via Kafka or RabbitMQ, no central controller) and Orchestration (a central Saga Orchestrator coordinates steps and handles compensation explicitly). Use Choreography for simple, loosely coupled flows. Use Orchestration when you need transaction state visibility across complex multi-step processes involving the Order Service, Payment Service, and Inventory Service simultaneously.
CQRS: Separating Read and Write Models for Performance at Scale
The CQRS Pattern separates read and write models entirely. Commands go to a write-optimised model; queries hit a separately maintained read model that can be denormalised or replicated for query performance. The complexity only justifies itself in systems with heavily skewed read-to-write ratios, product catalogue services, or reporting pipelines where read and write scaling must happen independently.
Pair the CQRS Pattern with the Event Sourcing Pattern: every state change is stored as an immutable event, the read model rebuilds from the event log, and the audit trail becomes a first-class architectural artifact rather than a retrofit.
Observability Patterns: Distributed Tracing and Log Aggregation in Production
A 2024 CNCF Cloud Native survey found that 62% of engineering teams cite distributed tracing as their most critical operational gap in microservices environments. A single user request in a 20-service stack touches 10 to 15 service hops. Without structured observability, debugging becomes archaeology.
Three pillars: Logs via the ELK Stack or Splunk for centralised log aggregation. Metrics via Prometheus and Grafana for service-level latency and error rate dashboards. Traces via Zipkin or OpenTelemetry for end-to-end request tracing across service boundaries. OpenTelemetry is the standard to build on in 2026 across cloud platforms.
The Sidecar Pattern is the deployment mechanism that makes this scalable. A sidecar container runs alongside the service in the same multi-container pod in Kubernetes and handles the instrumentation layer independently, so service teams stay focused on business logic. A service registry (Consul in most Kubernetes-native stacks) maintains the live map of available service instances, making service discovery a managed concern rather than a configuration problem that breaks under scale.
What Most Microservices Pattern Guides Get Wrong
A logistics firm came to us after three months of building Saga-based distributed transactions across six services. The flows looked correct in staging. In production, a service crash between a database write and a Kafka publish was silently corrupting downstream state. The Saga was sound. The Outbox Pattern was missing.
Pattern catalogues list patterns in isolation without showing how they interact or which critical pieces are missing from real production stacks. Three gaps appear consistently: pattern sequencing, observability tooling integration alongside patterns, and the Outbox Pattern.
The Outbox Pattern: Guaranteeing Atomic Event Publishing
The problem: a service updates its database and then publishes an event to Kafka. A crash between the two operations means the DB writes commits, but the event is never published. Downstream services hold a stale view with no error raised. Data protection breaks silently.
The fix: write the event to an outbox table in the same DB transaction as the business update, then a relay process polls the outbox and publishes it to the broker. DB-native atomicity guarantees at-least-once delivery. Without it, the distributed transaction safety the Saga Pattern provides is undermined by the publish gap.
How BuildNexTech Helps Engineering Teams Deploy Production-Ready Microservices Faster
The distance between knowing microservice patterns and instrumenting them correctly across a live distributed system is where most engineering time goes. Observability wiring, inter-service auth, Saga orchestration scaffolding- each takes weeks from scratch and days with the right expertise. BuildNexTech's AI services and automation platform handles the cross-cutting configuration that patterns like the Sidecar Pattern and API Gateway offloading are designed to centralise. Across 150+ clients in 30+ industries, including a US hospital system that reduced administrative burden by 40%, pattern instrumentation speed determines delivery speed.
What a BuildNexTech Microservices Instrumentation Rollout Looks Like
Four stages. Days one to two: Discovery, mapping the existing service topology and flagging gaps, including missing Circuit Breakers, absent distributed tracing, and Saga flows without the Outbox Pattern. Days three to five: Integration, wiring API Gateway configuration, deploying observability sidecars into multi-container pods, and setting Circuit Breaker policies. Days six to ten: Deployment, generating and validating Saga orchestration scaffolding against the Order Service and Payment Service flows. Week two onwards: Iteration, with teams owning the instrumentation layer as new independent services are added.
Who This Is For
Every mid-size organisation running Kubernetes-based microservice architecture currently manages inter-service patterns manually across cloud platforms. The trigger situations: distributed debugging taking more than two hours per incident, Saga compensation logic built ad-hoc per service team, or an upcoming monolith migration with no structured decomposition playbook. Serverless computing teams migrating to event-driven patterns will find the same sequencing framework applies. If that describes your team, the conversation is worth having.
Microservices Design Patterns Are a Sequencing Problem, Not a Catalogue
Microservice patterns are a layered system: decomposition patterns that safely break the monolithic application, communication patterns that keep independent services reliably connected with service-level loose coupling enforced, data patterns that maintain consistency without database sharing or two-phase commit, and observability patterns that give teams visibility across cloud platforms in production.
The gap between knowing these patterns and instrumenting them correctly across live software applications is where most engineering time disappears. The right microservice design patterns, applied in the right order with the right DevOps practices behind them, are what separate a system that compounds delivery velocity from one that compounds technical debt.
People Also Ask

What is the difference between the Saga Pattern and the CQRS Pattern in microservice architecture?
The Saga Pattern manages distributed transaction workflows across multiple services with compensating transactions on failure. The CQRS Pattern separates read and write models within a single service boundary. They solve different problems and are commonly used together.
When should I use Kafka vs. RabbitMQ for an event-driven architecture?
Use Kafka for high-throughput, ordered, replayable event streams and Event Sourcing Pattern implementations. Use RabbitMQ for task queues and point-to-point routing where message replay is not required.
How does the Circuit Breaker Pattern integrate with the API Gateway Pattern?
They operate at different layers. The API Gateway handles client-to-service routing and cross-cutting concerns, including user management and auth. The Circuit Breaker sits in the service-to-service call layer or service mesh and prevents cascading failures between downstream independent services.
How do Docker and Kubernetes support production-ready microservices design patterns?
Docker packages each microservice as a single container image. Kubernetes provides orchestration, including multi-container pod management, health checks, rolling deployments, and service discovery, making the Sidecar Pattern and database per service operationally viable at scale across cloud platforms.
What is the Outbox Pattern and why is it critical for data protection?
The Outbox Pattern guarantees atomic event publishing by writing the event to an outbox table in the same DB transaction as the business update, then publishing via a relay process. Without it, a crash between the DB write and the Kafka publish creates silent data inconsistencies that undermine data protection across downstream services.





.webp)
.webp)
.webp)

